How I Designed & Implemented Evals for Product Talk’s Interview Coach
What does generative AI make just now possible? This is a question that I’ve been obsessed with over the past few months.
While I’ve been primarily working alone, I don’t want to go on this journey in isolation. I believe there’s so much benefit to working out loud and sharing the ups and downs I’ve experienced along the way—especially because so much of the conversation around AI tends to go to one extreme or the other.
My goal with my contributions is to avoid the hype and offer an honest take of where this technology shines and where there’s still significant room for improvement.
Back in June, I offered my first webinar where I shared my learning journey up until that point. If you haven’t watched that webinar or read the transcript, that might be a good place to start.
At the time when I published that recording, I promised that it would be the first installment in a series, and now I’m back with the second installment.
In this edition, I’ll be doing a deeper dive into the topic of evals. Evals are an essential aspect of AI tool development that help you answer the question of whether your product is any good. And one of the reasons why I find evals a particularly rich topic is the fact that they allow us to engage in fast feedback loops, just like we do in product discovery.
You can watch the recording of the webinar or read an edited transcript below.
Full Transcript

Welcome everybody to Behind the Scenes, the Interview Coach. This time we're going to dive into evals.
If any of you have been to my webinars before, I usually do pretty polished webinars about product discovery. This webinar is very different. This is a behind the scenes look. It's going to be a lot more raw. It's going to be just me telling you what I'm building.
For the last four months, I’ve been building an AI product. I'm forcing myself on a weekly basis to work out loud.
I'm doing this as a way to build in a little bit of accountability to keep myself focused. And there's so much AI hype out there. I'm tired of it. I'm sure you're tired of it.
The last thing I want to do is contribute to the "product management is dead," "PRDs are dead," "AI is ending everything" conversation. I am exhausted with it, and this is the way that I found to continue to share and just to create a space for us to learn together. I know we're all trying to figure this stuff out.
I'm saying this at the start because I want you to know that I am not an expert in this topic. I am just like you. I'm learning how to do this. I took a class that helped with evals in particular. We'll talk about that class a little later, but I want you to think about today's webinar as Teresa's demo of what she's been doing.
A lot of people know my work on discovery—that's obviously a lot more polished. So I just want to start with the caveat: This is a little bit of a different show.
About Me and My Work

For those of you that are brand-new to my work, I'm Teresa Torres. I'm the author of this book, Continuous Discovery Habits. My day job is helping product teams make better decisions about what to build. Through Product Talk Academy, we offer courses on the discovery habits.
I'm sharing this because you're going to see the AI tool I built is in this context. I'm not trying to pitch you today. I'm just trying to share what I'm doing.
As part of our Academy, we have a number of courses that are on different habits. Some of our courses include Defining Outcomes, Continuous Interviewing, and Opportunity Mapping.
The Genesis of the Interview Coach

In the spring, I broke my ankle in a hockey game and I had to have ankle surgery. I was laid up for about three months and had to stay off my feet. I had a lot of time on my hands and I decided to dive into this question: What does generative AI make just now possible? This phrase—just now possible—is from a Marty Cagan blog post. It really resonated with me.
I really thought about this question in the context of our courses. I want you to imagine it's late March, early April 2025. This is a true story. I was sitting on my couch, foot propped up, recovering from ankle surgery, and I started to wonder what's just now possible due to generative AI. I was thinking about it in the context of our Continuous Interviewing course.

In this course, we teach product teams how to conduct effective customer interviews. I teach a very specific brand of interviewing where students learn how to collect specific stories about past behavior. This course is all about what to ask, how to listen better, and really how to collect a full, rich customer story.
All of our courses try to draw on what we know from research. Students come to class and we actually interview each other, so it's a very hands-on practice oriented class. That's because I'm a big advocate of deliberate practice.
Deliberate practice is this idea that the way we build skill is we practice it and then we get feedback on that practice. The feedback is really critical.
In class, we give students a rubric so they can practice together and then they can give feedback according to the rubric. But our students aren't experts in interviewing yet, and deliberate practice really requires expert feedback.
One of the questions I started to noodle on in April was: Can we help students give each other better feedback on their practice interviews? Because I'm a learning wonk, I sort of framed this as: Can we model what good feedback looks like? This really led to some very early experiments with what is today Product Talk's Interview Coach. That's the AI product I'm going to talk about and dive deep into evals on.
A Quick Introduction to My Technical Background
Let me share a little bit about my background. I started my career in the late ‘90s. At that time, I was an interaction designer. But for those of you old enough to remember, companies weren't exactly hiring designers straight up. A lot of us were working in hybrid roles where we were actually front-end developers also doing the design work. So early in my career, I wrote code. I was a front-end developer and designer. Then later I moved into product management.
This is relevant because you're going to see I get into code quite a bit here, but I cannot emphasize enough—at the beginning of this project, I didn't really identify as an engineer.
Another part of this story is about three years ago I read the book Ask Your Developer by one of the founders of Twilio, and that book really had a big influence on me. It's about how code can help you run a business and it really opened my eyes to how much in my own business running Product Talk and Product Talk Academy I was doing manually or with human help where really I should have been using code.
About three or four years ago, I started to get back into coding. I share this so that you know that I'm not a coding novice, but I'm certainly not a coding expert.
I want those of you that don't code at all to get a really clear picture of what's possible and where you might need some engineering help.
My goal today is to make evals really accessible, to share how I learned about this and how I'm putting it together for a more complex product than I originally thought.
How the Interview Coach Works
Here's how it works. Students conduct a practice interview. That could be in class or it could be on their own time. They record it. They get a transcript. We provide tools that help them upload a video and we give them an SRT file. If you're not familiar with SRT files, they're closed captioning files. They include the full transcript with timestamps.
That file gets uploaded to the Interview Coach. Students submit it in our course platform as homework. Pretty quickly afterwards, they get an email. The email is their very detailed Interview Coach feedback.
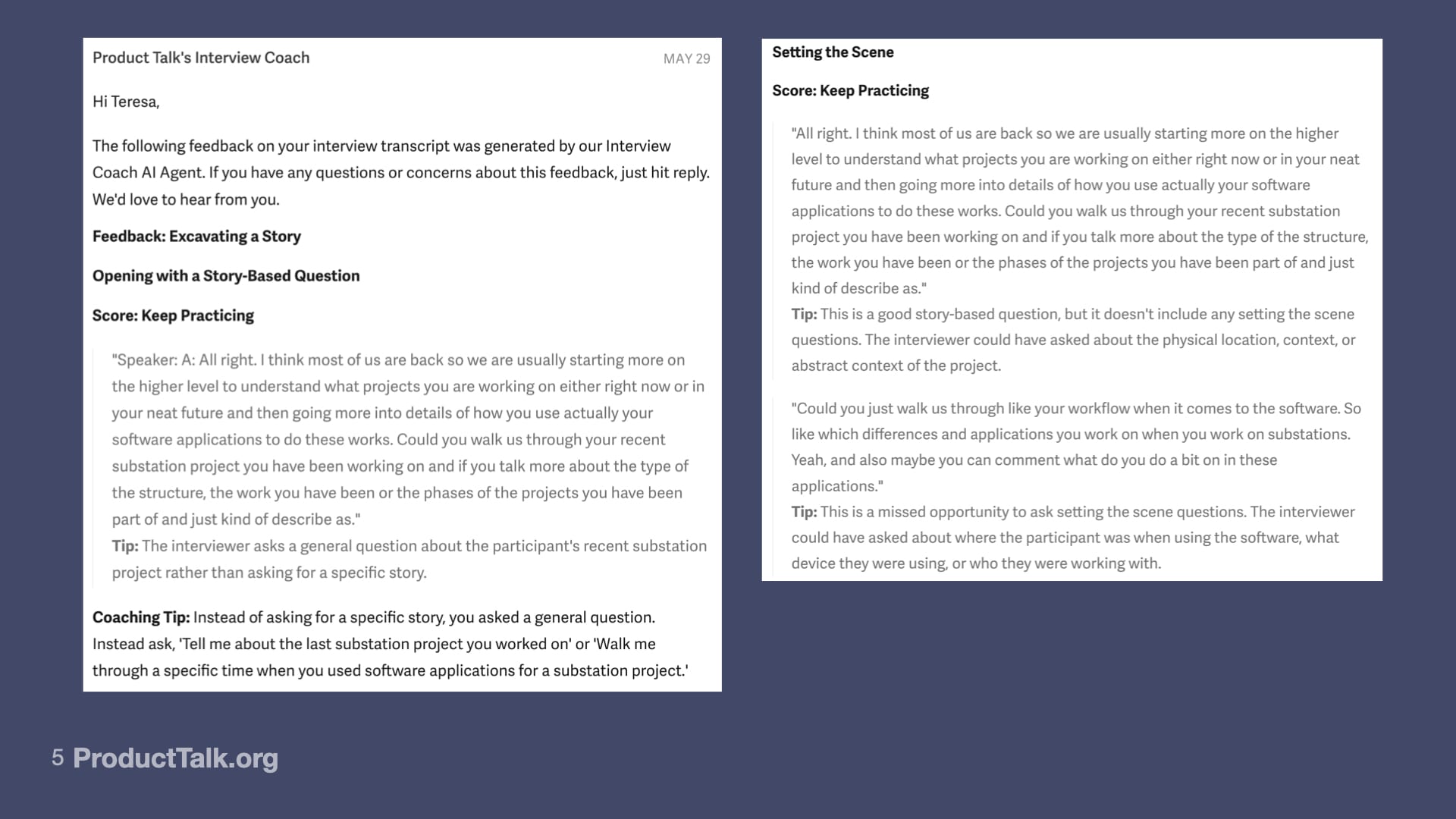
We're telling them straight up this feedback is coming from our AI Coach. We're being very transparent about that. A big part of that reason is we are in beta. There are still some known issues with this Coach. I still review literally every single email that goes out. This is a big part of my error analysis, which we're going to talk about in a few minutes.
The way the email is structured is that this instance of the Interview Coach gives feedback on four different dimensions. In the course, we teach collecting a story by teaching opening with a story-based question (dimension one), setting the scene (dimension two), building the timeline (dimension three), and redirecting generalizations (dimension four). This is the rubric we use in our course to teach interviewing.
In any given section, it's telling you the section name and giving you a score. There are three values: “Keep practicing,” “Getting it,” or “Great.” We're trying to encourage people here.
Within each section, we pull out a real excerpt from the student's interview. Then they get a tip about how to improve it and they get an overall coaching tip for the section.
The Interview Coach is doing a deep analysis of an interview.
The Problem: How Do I Know If My AI Product Is Good?

As I was building this Coach, I was looking at all these emails going out to students. The Interview Coach was pretty good, but I was noticing some problems. I'm kind of a perfectionist, especially when it comes to teaching. I really wanted to make sure my Interview Coach was really good.
I was trying to determine how I could know if my AI product is good. As I iterate on it, how do I know that my changes—whether they're model changes or prompt changes or temperature changes—are having any impact? This is what led me to learning about evals.

When I first learned about evals, I was pretty confused. Everybody defines evals differently. I'm just going to share three of the very early things I read that introduced me to evals, and then I'm going to share my simplified version of all of this. If you're confused about evals, I get it. There's a lot of confusion out there.
This first definition actually comes from OpenAI. It sounds like OpenAI is basically saying: Create some test inputs and then analyze the results. OpenAI is defining an eval as: Create a bunch of inputs, run them through your LLM, and then analyze the results.
Here's where I got stuck right away: Where do I get interview transcripts from? I know synthetic data is a thing, and I played with how to create synthetic interview transcripts. It's hard.
An interview transcript is a lot of text and it needs to be realistic. I need to simulate what interviewers are like as they're learning how to interview and account for all the variations. This felt very overwhelming to me.
I started to learn about all these eval tools. I think I posted on LinkedIn and someone responded, "What eval tool are you using?" And I asked, "There's eval tools?" So I started to dig into the eval tools and I started to find these very technical Python packages. What was interesting about this one is it started to talk about evals as code. I was like, "Oh, evals aren't just data sets or defined inputs. Some people are defining evals as code."
Then Aman Khan wrote this blog post for Lenny's Newsletter. He really started to get into what evals are. The thing that really resonated with me here was he defines evals in three different ways. We have human evals where humans can define whether it's this OpenAI definition, we can do it in code, and we can also do it with LLM-as-Judges.
That's when I got introduced to this idea of LLM-as-Judges, where you use another LLM to judge your LLM. This sounded exciting to me, but I was a little bit confused. This was a lot to learn all at once.
I ended up taking a class on AI evals (get 35% off if you register through my link). I've now built several AI evals. I have data set evals. I have code evals. And I have LLM-as-Judge evals. I have done a ridiculous amount of human labeling.
Here's how I want you to think about evals: Evals are just how we're going to evaluate if our AI product is good or not. If you're familiar with unit testing or integration testing, a lot of people in the AI engineering space are starting to talk about evals as analogous to unit tests and integration tests.
Let me explain that analogy for my non-technical folks. When your engineers write code, like functions and processes, they're writing unit tests for every function, every micro thing. The unit test is testing the logic of that thing. For a piece of code, they might have half a dozen, a dozen unit tests, and it's thoroughly testing: Does the code work the way that we expect?
An integration test is when we have a lot of these pieces of code that are all unit tested. Now we need to test: Do those things work together properly?
For those of you that work in an environment where you have a production product, odds are you have lots of unit tests and integration tests, and these get integrated into your CI/CD pipeline.
The way a lot of teams run these is, before you push to production, all these tests run on any code change, and they tell us: Is our product working the way that we expected? That's what allows us to have a lot of confidence that our product is working.
Conceptually, I want you to think about evals as a way to evaluate whether your AI product is any good.
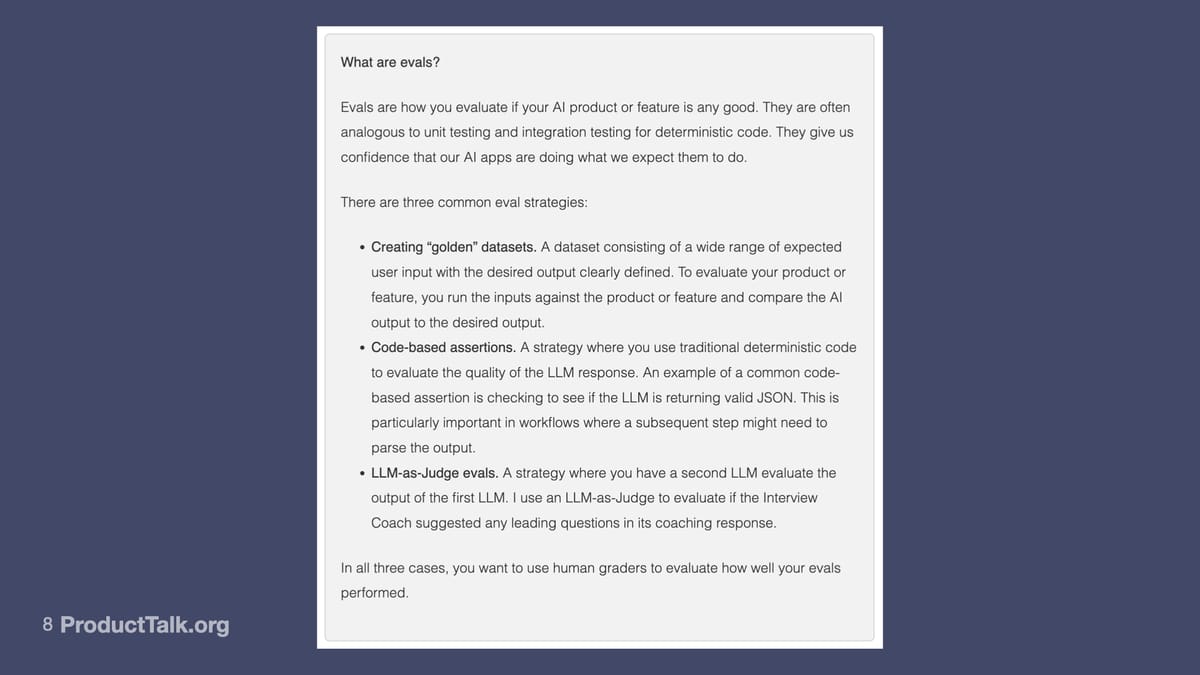
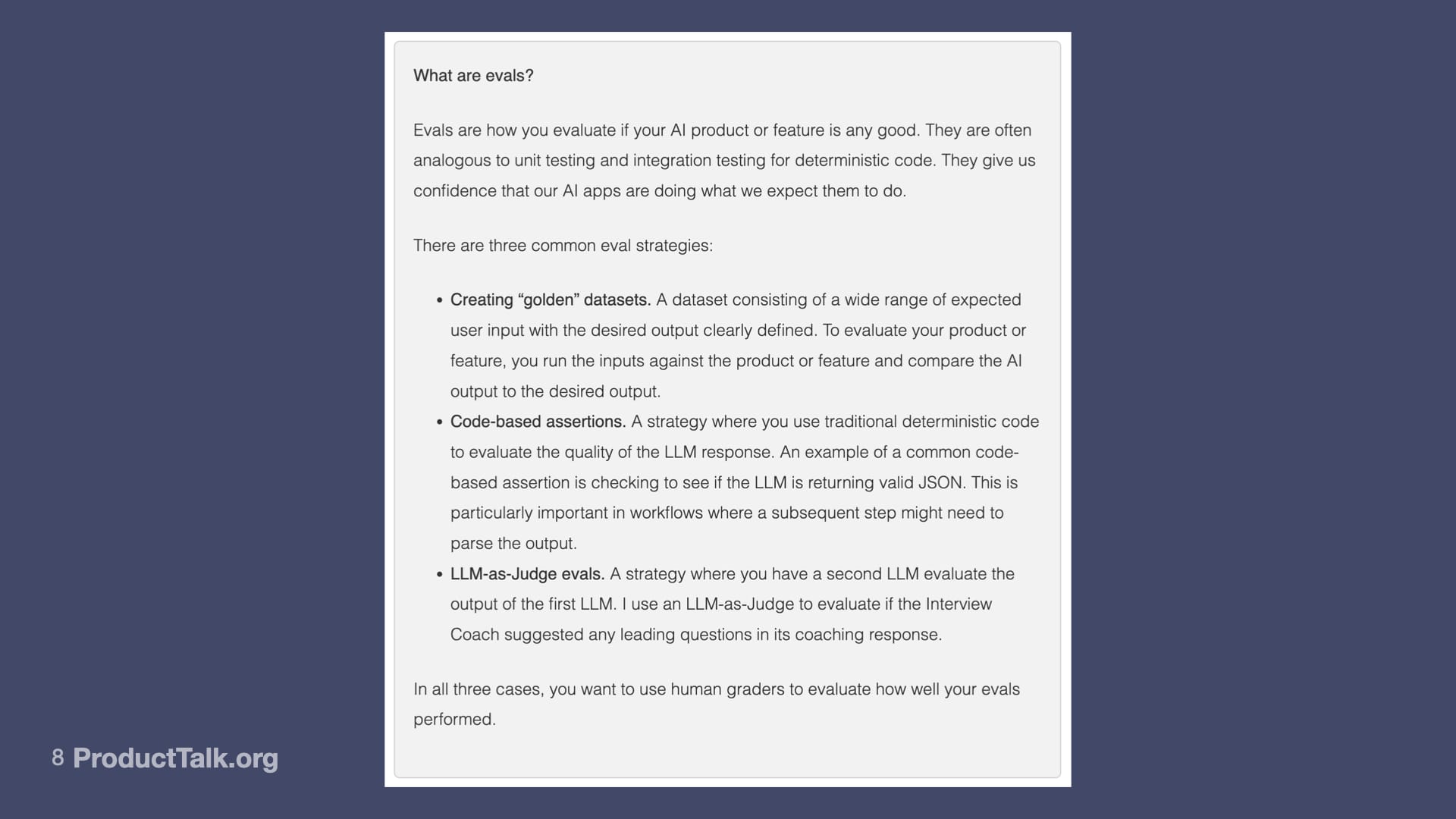
There are three primary ways of doing evals. One: We can create data sets where we define specific inputs and their expected outputs, and then we give the LLM all those inputs and we compare the outputs to our clearly defined outputs. And we’re grading the LLM based on how closely their output matches what we expected.
Another type of eval is code-based assertions, where we’re basically saying we’re going to use code to look at the LLM’s response and evaluate it. We’re going to look at a couple of code-based assertions. A really common one is, for example, my LLM calls return structured JSON. I use a code assertion to validate that JSON. Is it what my code is expecting?
And then the third type is an LLM-as-Judge, where you’re basically sending the output to another LLM and asking it to score it based on some dimension.
I started to play with these ideas on my own, and one of the ideas that I ran into—especially with the LLM-as-Judge evals—is once you have an LLM judging another LLM, it starts to feel like an infinite loop. Don’t I need an eval to judge my LLM-as-Judge that’s then evaluating my product? And where does that loop end?
And I wasn’t really sure how to set up my data sets. I posted on LinkedIn. I got some help. The responses were very overwhelming. Everyone told me to use these eval tools that scared me.
The AI Evals Course on Maven
It was about this time when I landed on the AI evals course. I really was asking this question: How do I have confidence in my evals?
This course is called AI Evals for Engineers and Product Managers on Maven (get 35% off if you register through my link).
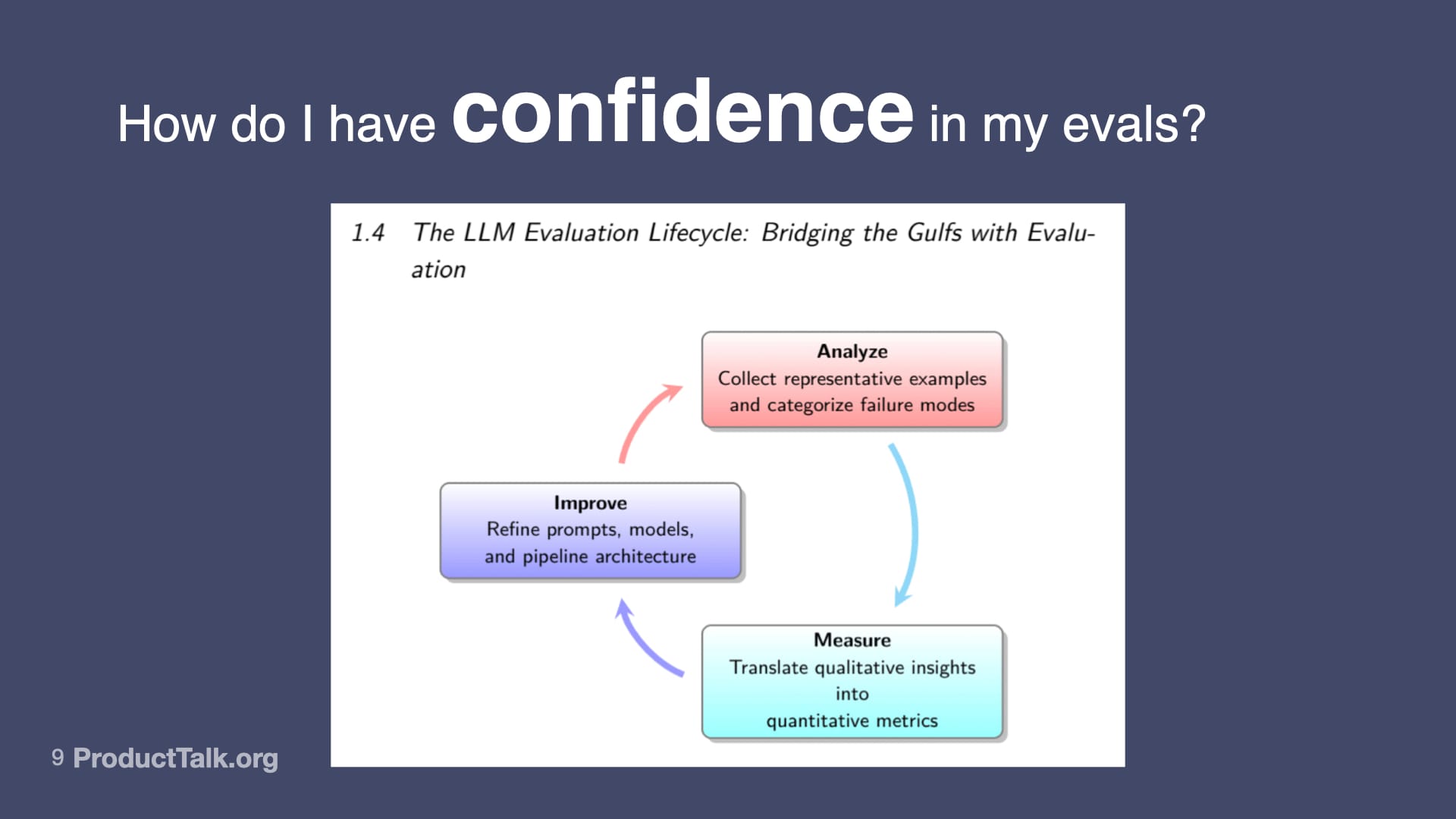
This visual they shared in class one immediately resonated with me. For those of you that are familiar with my product discovery work, this resonates quite a bit. They talk about evals, the eval loop as you first have to analyze your data. You're looking at your traces. You're going to analyze your data. You're going to put metrics around it so you can measure what's happening. You're going to make an improvement and then you're going to reanalyze again.
What we're seeing here is a feedback loop, which by the way is what product discovery is all about. I was giddy on day one because I was like, "Oh, these are my people." This really answered the question for me of how I can have confidence in my evals. I'm basically following the scientific method. It's very analogous to what we do in product discovery.
Understanding Traces
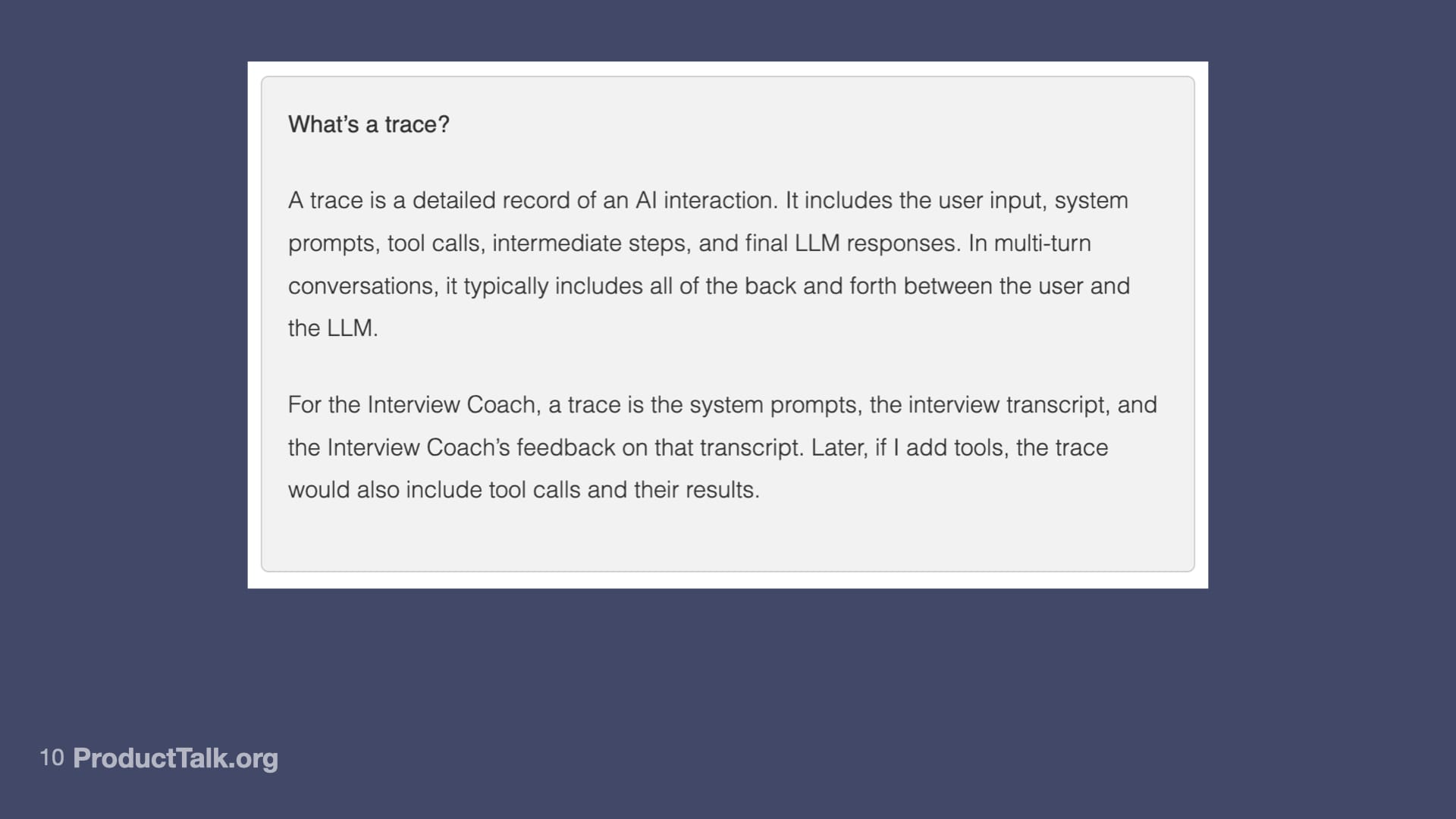
Let me explain what I started doing and what I learned in the course. Let's talk about a trace because this is going to be one of the most important concepts we talk about.
A trace is a detailed record of an AI interaction. If you use ChatGPT in the web browser, the trace would be the underlying system prompt, the data that you entered into ChatGPT, ChatGPT's response, and all the back and forth. A trace is a full record of a user's interaction with the AI system.
For the Interview Coach, a trace is my system prompt, the interview transcript, and the Interview Coach's feedback.
This idea of a trace is really important because in the “analyze” step, we're going to be looking at traces. We're looking at what actually happened.
When I learned about this and that all these AI companies were looking at traces, at first I was a little scared. I was like, "Whoa, AI companies are saving all this data? My AI conversations aren't private?" So this raised a lot of ethical concerns for me.
One of the things that I wrote about in an earlier blog post is how those of us building AI products have a responsibility to communicate to our users that we are logging these traces. We have a responsibility to tell them our data policies.
With the Interview Coach, when you go to upload a transcript, you are consenting to letting me store your interview transcript and your LLM response for 90 days. I'm completely upfront with that because I believe that is good data practice.
Building My First Eval System
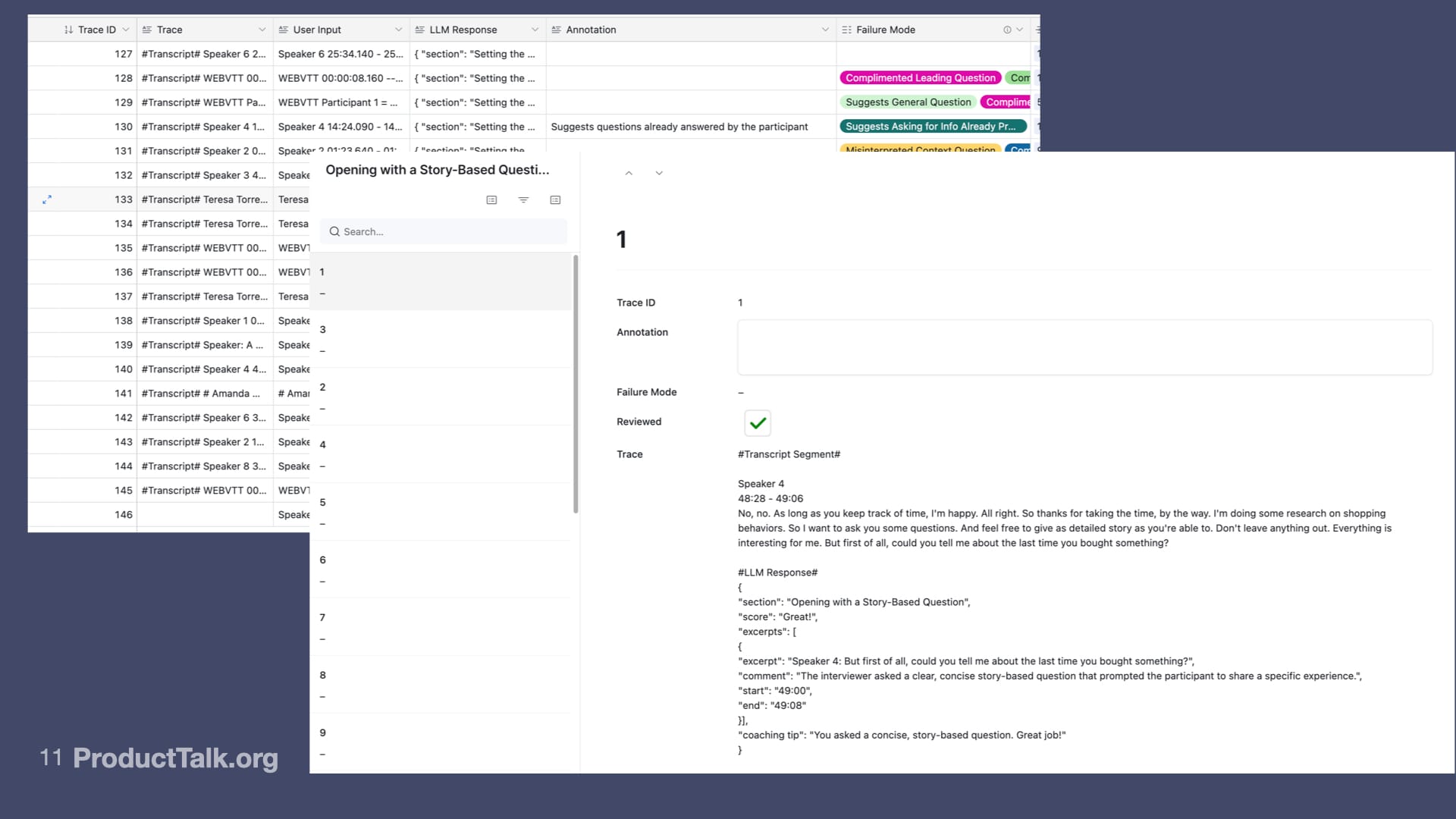
I started logging my traces in Airtable. Now, I wouldn’t necessarily recommend this because Airtable's performance right now is pretty terrible, and transcripts are long. Why did I do this? I did this because this was a tool that I was familiar with. I was already learning a lot and I was trying to minimize how many new things I had to learn at once.
What you're looking at here is my database of interview transcripts. You can see that I have the user input as the transcript. The LLM response is the Coach's response stored in JSON. One of the things we learned in the class is to analyze your traces and to look at what feedback you have on that trace. As a human, do you think the Coach's response was good or not?
For the very first annotation tool for human labeling, I actually used an Airtable interface. I didn't build any tools. I didn't use any of the off-the-shelf eval tools. I just started with what I had.
I have a trace. I have the LLM response. I have the interview transcript. I have a little box to type in my annotation. Then failure mode—what I'm doing here is I'm first just writing my thoughts. Do I think the Coach did a good job? Where were there errors?
After I do that for a set of traces, I'm looking across my traces and I'm asking, “What are the most common failure modes?”
These are my annotations. This was my very first round of error analysis. You can see a lot of my traces have errors. I'm writing notes on a lot of them. These are my failure categories. A lot of traces have multiple failure categories.
The first time I did this, I was like, "Holy crap, my Interview Coach sucks." I was very disappointed. There were errors all over the place.
The Error Analysis Process
The very first thing is we have to analyze our data. We have to look at our traces and see what mistakes our AI product is making. Then what you're going to do is you're going to take the most common failure modes and you're going to look at: Can I build an eval that measures that?
If we go back to our loop, it was: analyze, measure, improve. I've analyzed, I’ve found my most common failure modes. Now I need to come up with metrics. Can I measure how often each of those failure modes are occurring in my production traces? That's what an eval is doing.
An eval is the code that we're writing, whether it's data sets, code assertions, or LLM-as-Judges. The goal with the eval is: Can we get an accurate measurement of how often this error is happening?
This is one of my biggest takeaways from the class. All of you can go buy an eval tool off the shelf and it's going to measure a bunch of things. But what the eval tool is measuring is not necessarily the problems that are coming up in your product.
They hammered on this idea: You have to do error analysis because errors are really use case specific. If we don't do the error analysis, we don't know what errors to measure.
This to me is one of the most important parts of this entire talk: You have to do the error analysis to figure out what to measure in the first place.
There were two error modes right away that really concerned me. Remember, a student is submitting an interview transcript and the Coach is giving them feedback.
Sometimes in the feedback, the Coach might say something like, "You missed an opportunity to build the timeline here, you should have asked what happened next."
Sometimes in the feedback, the Coach will suggest a question the interviewer should have asked. Two of my most common failure modes were related to questions that the Coach suggested the interviewer ask. The problem is, sometimes the Coach suggested a leading question or a general question.
I want to be really clear here. It's not that the interviewer asked a leading question or a general question. It's that the Coach suggested to the student that they should have asked a leading question or a general question.
To me as a teacher, this is a catastrophic failure. I don't want my Coach teaching my students bad habits. We don't want them asking leading questions. We don't want them asking general questions. We want them to keep their participant grounded in their specific story.
These error modes were really concerning to me. These were actually the first two evals that I wrote.
Learning to Use Jupyter Notebooks
When I sat down to write evals, I had never written evals before. Remember, I coded a little bit, but I didn't really know how to write evals. I started in Apple Notes. When I code, I always like to write pseudocode in plain English first and then try to write real code.
I was in an Apple Note writing pseudocode and I was really getting frustrated because it kept turning regular quotes into smart quotes in my JSON. Then I would put it in my code editor and I'd have all these stupid errors and I was getting really frustrated.
My husband is also an engineer. At that point he said, "Teresa, you should use a Jupyter Notebook." And I said, "What in the world is a Jupyter Notebook?"
For those of you that have never worked with coding notebooks, here's what a notebook gives me. This cell up here at the top is markdown. These are my notes. So this is my name of my function. I'm defining the inputs, I'm defining the outputs. When I started this, the markdown wasn't just inputs and outputs, it was my pseudocode. It was where I started to think through: How am I going to build this eval?
I needed a space where I could go back and forth between brainstorming ideas and then writing code. For those of you that have written evals, it often takes multiple tries to get the eval right. To be able to go back and forth and have your notes right there and to be able to run the code in the notebook was really powerful for me.
Here's what I'm going to tell you. Don't follow my atrocious work habits, but I started this on a Sunday. I downloaded a notebook for the first time. I had never written any Python. I'm a Node.js programmer. I literally opened ChatGPT and said, "How do I use a Jupyter Notebook?"
The reason why I used Python instead of a language I know well is because I had learned in the class that Python has these amazing visualization tools that I wanted to use.
A notebook gave me a space where I could combine my notes plus my code that I could execute, plus data visualizations to allow me to dig into the data. That's what I was getting out of a notebook, all in one file. I was not familiar with these tools when I started. I relied heavily on ChatGPT to get me through it.
Again, I started this on a Sunday. I had never used a Jupyter Notebook. I had never written Python. By Thursday, I had my first set of running evals.
My First Two Evals
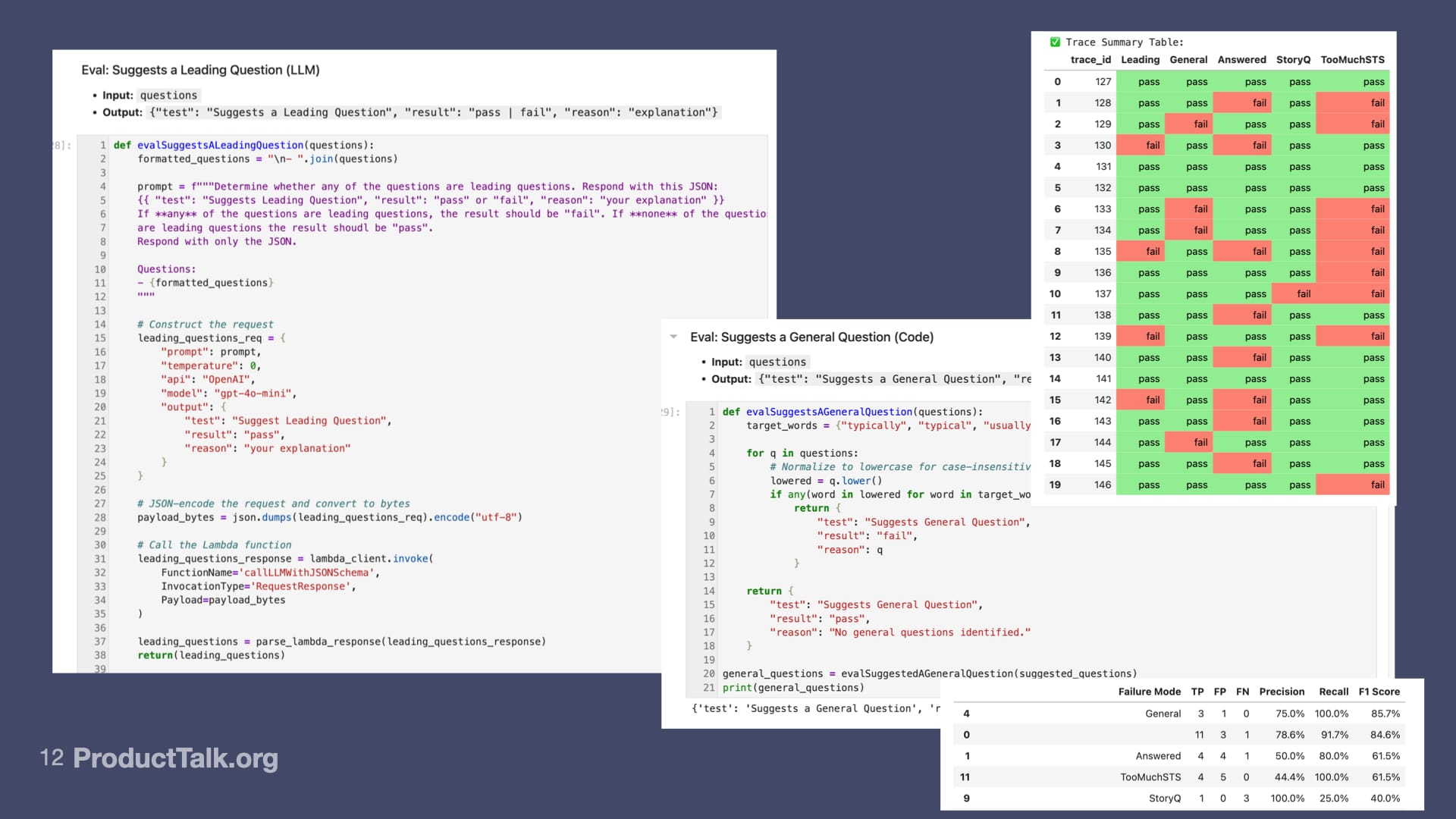
What we're looking at here is a "suggests a leading question" eval. This is actually an LLM-as-Judge eval. There's a prompt explaining to an LLM what a leading question is. All this eval is doing is it contains a prompt and I'm taking a prompt and a question and I'm sending it to an LLM and I'm asking: Is this a leading question?
This is my LLM-as-Judge eval. Remember, I'm trying to measure across my traces: How often is the Coach suggesting a leading question?
It turns out this worked really well. LLMs understand leading questions really well. I had to tinker with this a little bit. I think I started with, "Here's all the questions. Are any of them leading questions?" I experimented with one question at a time. I had to extract the questions.
As part of my eval setup, I have a bunch of helpers. I do a lot of processing of a transcript and of an LLM response before I send particulars to my evals.
One thing I've learned is to do an eval well, you have to really control the context you're giving the LLM. I didn't give the LLM: "Here's the full coaching response. Are there any leading questions?" That didn't work very well.
I pulled out all the questions the LLM suggested and I gave it specific questions and said, "Is this a leading question?"
This is part of that experiment that I was talking about. The value of doing this in a notebook is I can keep notes up here of what I've tried and what has worked and what hasn't worked. Down here I'm iterating on the code.
I can actually have separate cell blocks for all my different experiments. One cell block could be all the questions. One cell block could be one question. One cell block could be the full LLM response. It allows me to run experiments in parallel and measure which eval is performing best.
I mentioned that the Coach was also suggesting general questions. A general question is "Tell me about your typical morning routine." I don't want someone asking that question. I want them asking, "Tell me about your morning routine today." We're talking through a specific instance.
This is actually a code assertion eval. I'm just looking for keywords: typically, typical, general, generally, usual, usually. This is a really crude eval. It actually works very effectively. It is very aligned with my human labels. This also taught me: Start with the simplest, dumbest eval, because it might work. This is a code assertion eval.
This is an LLM-as-Judge eval. This was really helpful for me. Remember, it was hard for me to come up with a data set for interview transcripts.
To write these evals, I had to write a bunch of helper functions. My helper functions are taking the LLM response, parsing out all the coaching tips. From the coaching tips, it's parsing out all the questions so that these evals aren't getting a lot of context that's irrelevant to their task. They're just getting the questions they're trying to evaluate. This is going to become pretty important later on.
The evals are more than just this code. Behind the scenes, I'm doing some transcript and LLM processing to support more efficient evals.
My First Results
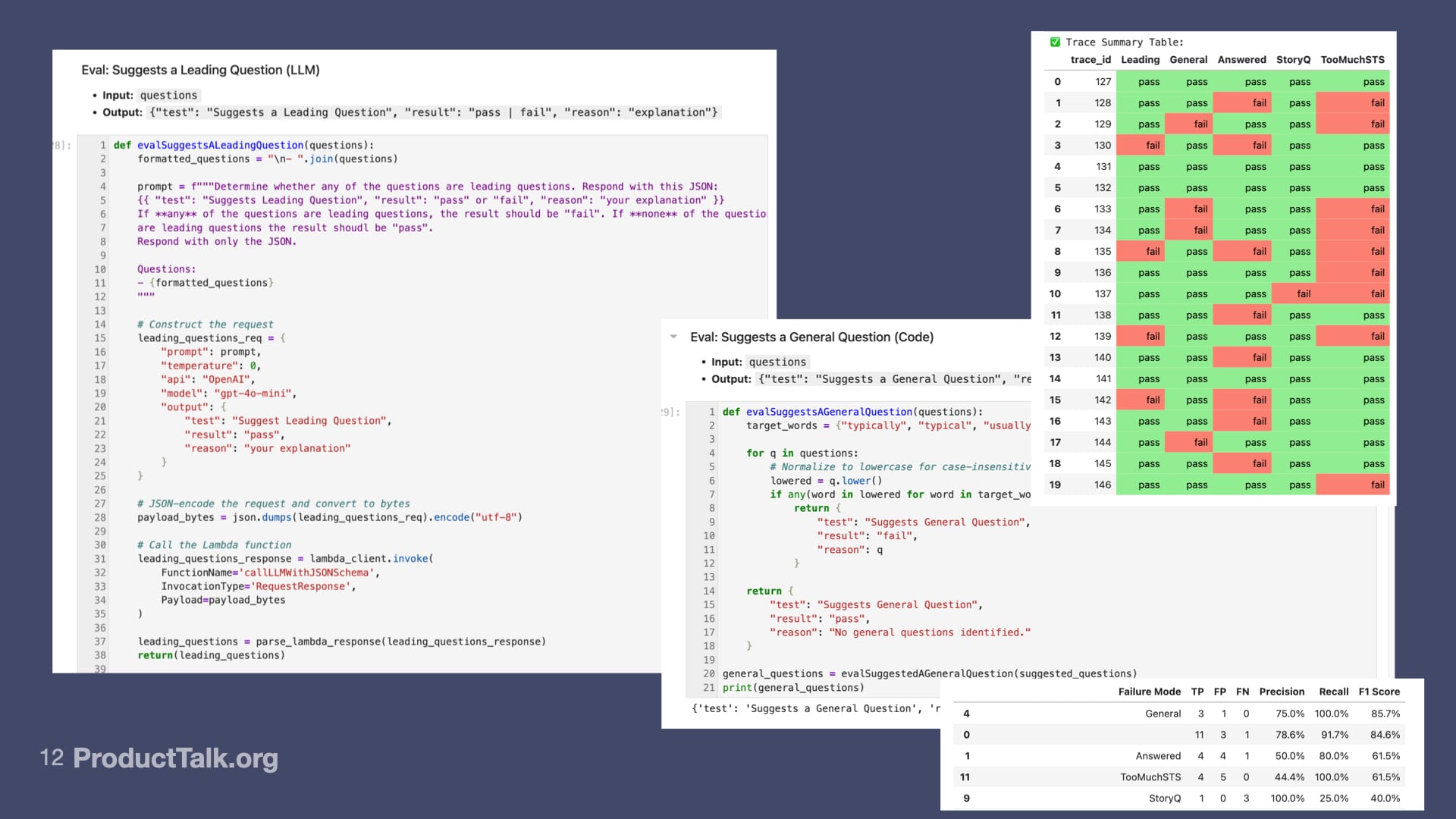
Then I ran these evals. I wrote five evals. I ran all five evals on my dev set. My dev set is just my traces that I'm using to support development.
In my very first run, I started on a Sunday. By Thursday, I ran my five new evals across a set of traces. In four of my traces, the Coach suggested a leading question. In four of my traces, the Coach suggested a general question.
It looks like this is failing a lot. This eval is: Is the Coach suggesting a question that the participant already answered?
This was a weird one. Sometimes the Coach would give feedback on the story-based question in a subsequent dimension. That’s pretty rare, but it did happen.
This one was really interesting. It looks like too much STS. This is because the Coach thinks every question should be a setting the scene question.
The whole point of the interview is to build the timeline. We only want a few setting the scene questions, but this dimension was greedy. It wanted every question to be a setting the scene question. You can see I have a lot of failures here.
Just by doing my first run, I can start to get a visual representation of how good my Coach is. But I have a problem. This visual representation is only helpful if my evals are good.
Scoring My Evals
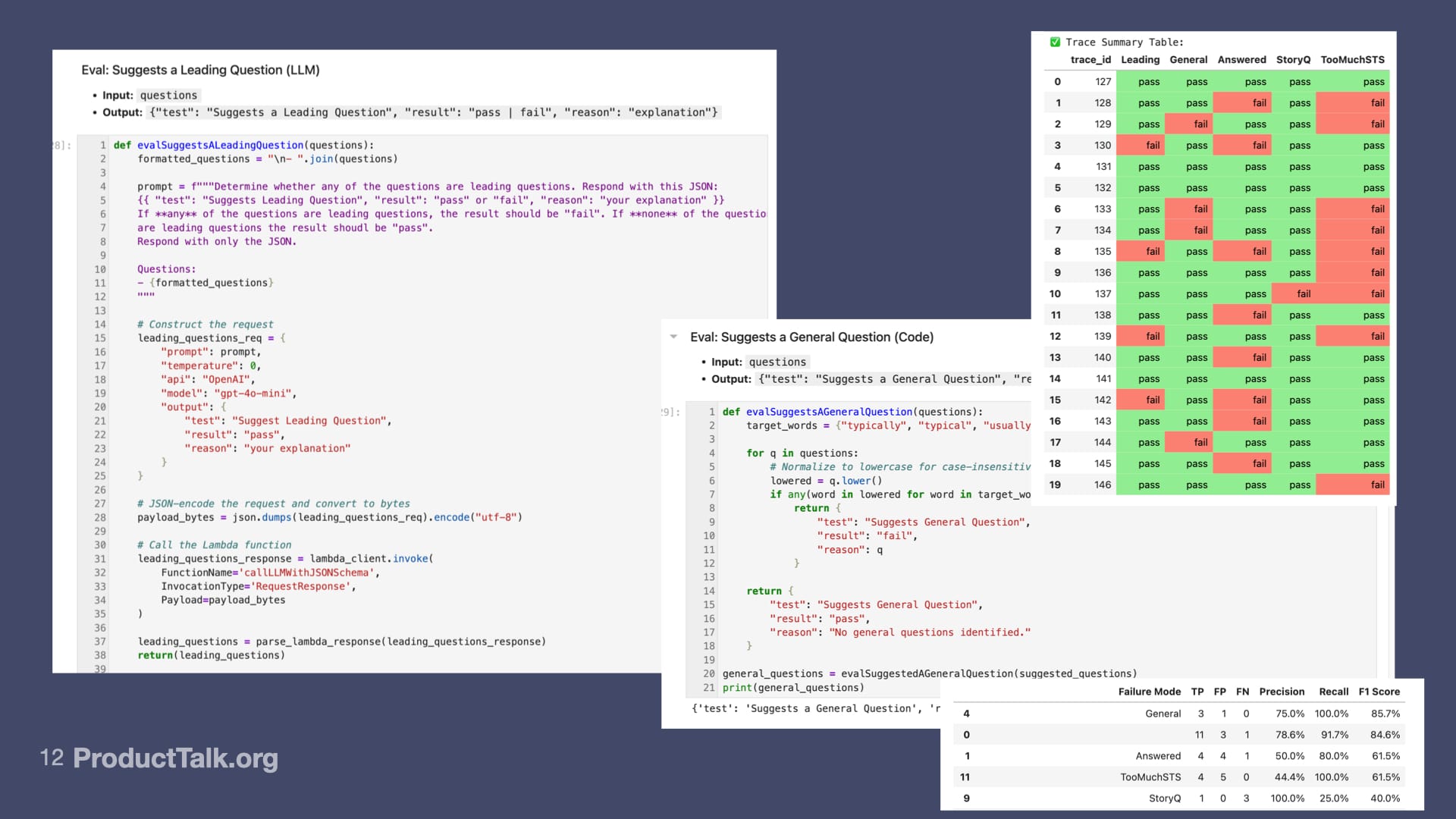
The next thing we learned in the class was: How do we score our evals? How do we know if they're any good? What we learned was to compare our eval output to our human label output.
I labeled all these traces. That was part of my error analysis. Now I'm going to compare what my evals found to what I found. That's going to give me some scores.
You can see my very first run of scores were kind of hit or miss. They weren't that great.
For my general question eval, it looks like there were four instances. Three of them were true positives. That means they matched my human labels. One of them was a false positive, which means that the eval labeled it a general question, but I did not.
This table is telling me: Where did my label differ from the eval label? I want to align my LLM-as-Judges with my human labeling. You might think I just want the LLM-as-Judges to match my judgment completely. But that's not what happened in practice.
When I actually looked at this data—and by the way, this is where working in a notebook really helped because my notebook generated this table. By working in a notebook, I’m getting these visualizations.
I looked at this one, "too much STS," I realized in writing the eval for determining what is too much setting the scene, I was revising my rubric. When I did human labeling, I was just using my intuition: "That feels like too much STS." When I had to write an eval, I had to write a deterministic way to evaluate too much STS. It turns out my deterministic evaluation was better than my human intuition.
When I started to compare my eval’s output to my human output, I actually liked my eval output better. This is really critical because now this is giving me feedback about how I can teach this to my students. It's giving me feedback about how I can teach this to my Coach.
One of the really surprising things about this whole process is I started to learn better about my own material that I teach. By trying to train an AI how to do this stuff, it's helping me better understand what I teach and what I've been teaching for years. This was mind-blowing to me.
There is a lot of critical thinking in this. What we’re talking about here is data science. There’s a lot of looking at the data, analyzing it, figuring out what’s going wrong, coming up with a hypothesis, writing an eval, looking at the data, aligning with the human. I actually really loved this process. It was a lot of fun.
I realized that as the product manager, I need to be involved in this process. Yes, there’s a lot of engineering work here, but if I just hired an engineer to do this, no engineer without my expertise is coming up with this really simple code assertion eval of looking for “typical,” “typically,” “usual,” “usually.”
I’m able to generate that because I’ve seen general questions over and over again and I’m confident that language captures them. I have to teach the LLM what a leading question is. That’s my expertise as an instructor.
This started to raise a question for me about how in the world product teams are going to do this. We really have to cross-functionally collaborate closer than we ever have. Because it’s probably going to be your engineer writing code, but your product manager or designer are probably going to be involved in prompt design or even eval design.
The Value of This Process
This was round one. Sunday through Thursday, I wrote five evals, I ran them across my traces, I got my summary, I scored my judges and I'm like, "Okay, I have some work to do."
Here's what was great about just getting to this point. Now I can start to look at: Are my evals any good? I'm looking at aligning my evals with my human scoring. I learned a few things.

Writing evals helped me evaluate just how often my most concerning failures were happening. I had this question of: Is my Coach any good? Well, now I can see, 4 out of 20-ish times, it suggests leading questions. Four out of 20-ish times, it suggests general questions. I can see which failure modes I needed to dig into. This is my dashboard. It's telling me how good my Interview Coach is.
That was very helpful to me because I'm putting this in front of real students. I want to know what's happening.
It also helped me find bugs. One of the things that I noticed is that it looks like this error is happening a lot. But what I learned when I dug into this, is actually when I was pulling questions out of the Coach's response, some of them were questions where the Coach was saying, "You asked a good question" and it was saying what the question was. And that was getting included in the list of suggested questions and that's wrong.
A lot of these failures weren't actually failures. This helped me find some bugs in my core system, which was really helpful.
As I already mentioned, it helped me get further clarity on my rubric. Doing this process is actually helping me improve my course and helping me improve teaching these concepts.

How do I know if my Interview Coach is any good? I can now run my traces against my evals and get a score. How do I know if my model prompt temperature changes are having any impact? I can now A/B test them. I can run all my evals against what's in production. I can run all my evals against my proposed change and I can look at this grid and evaluate: Is my change better?
I now have a fast feedback loop. I can make changes, I can run my evals, I can evaluate the impact, I can decide whether or not to release. Especially as a discovery coach that’s all about fast feedback loops, I love this process. Now I can make a change and I can confidently decide: Is this worth releasing?
Where I Am Today
This is where I got from Sunday to Thursday. This was back in late May, early June. At this point, I was working in Airtable and a Jupyter Notebook, period.
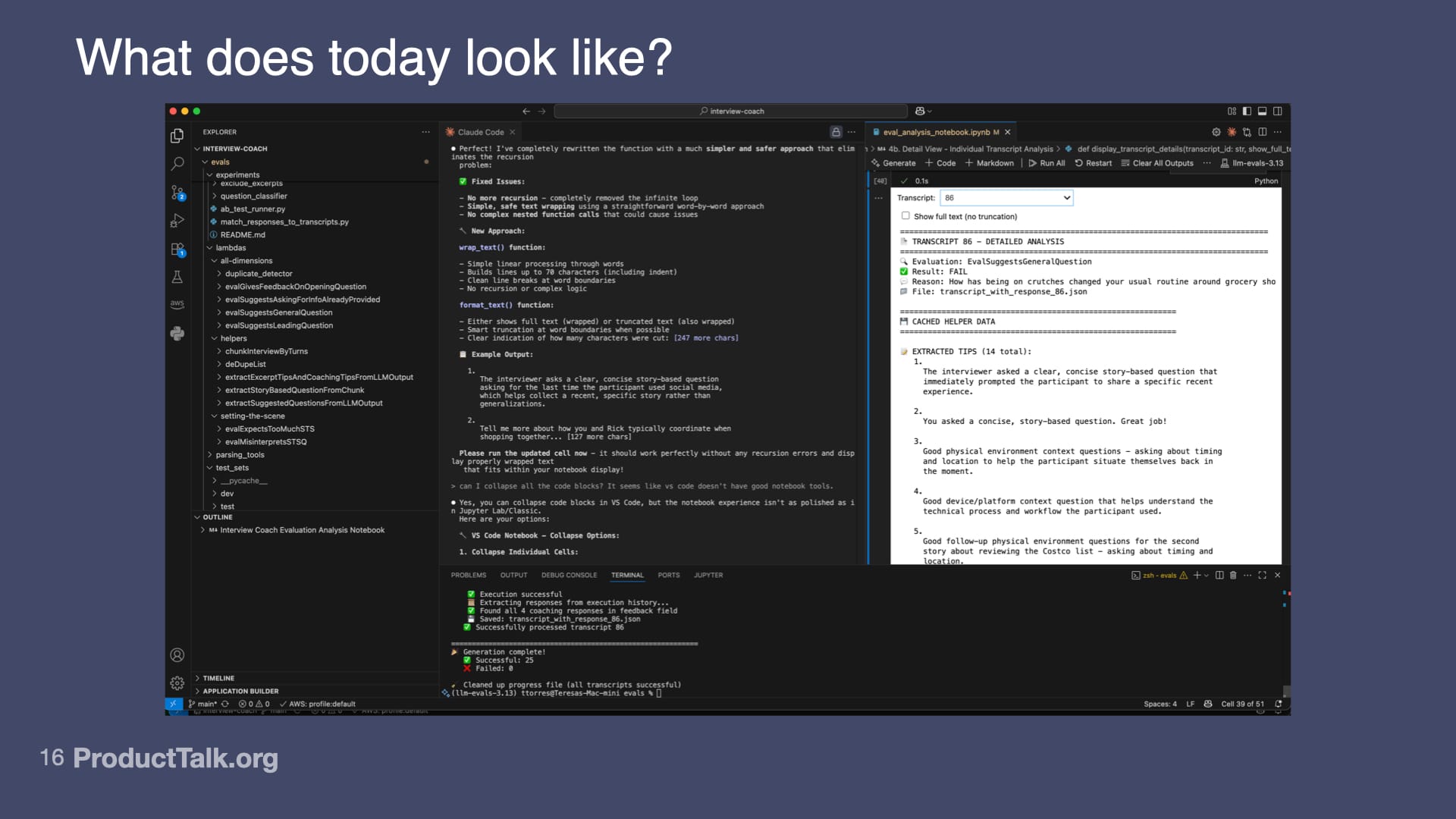
Since then, a few things have changed. I have now moved to VS Code. The reason why I moved to VS Code is because I want Claude right there in the IDE with me. I want Claude to have access to my projects.
I also have moved my eval code out of notebooks into real code. I know I can commit my notebook to GitHub, but I want to run some of my evals on production traces as guardrails. In order to do that, I need my eval code to be in my repo, deployed in my dev and prod environments.
Now all my eval code is part of my normal code repository and I'm using my notebook for data analysis.
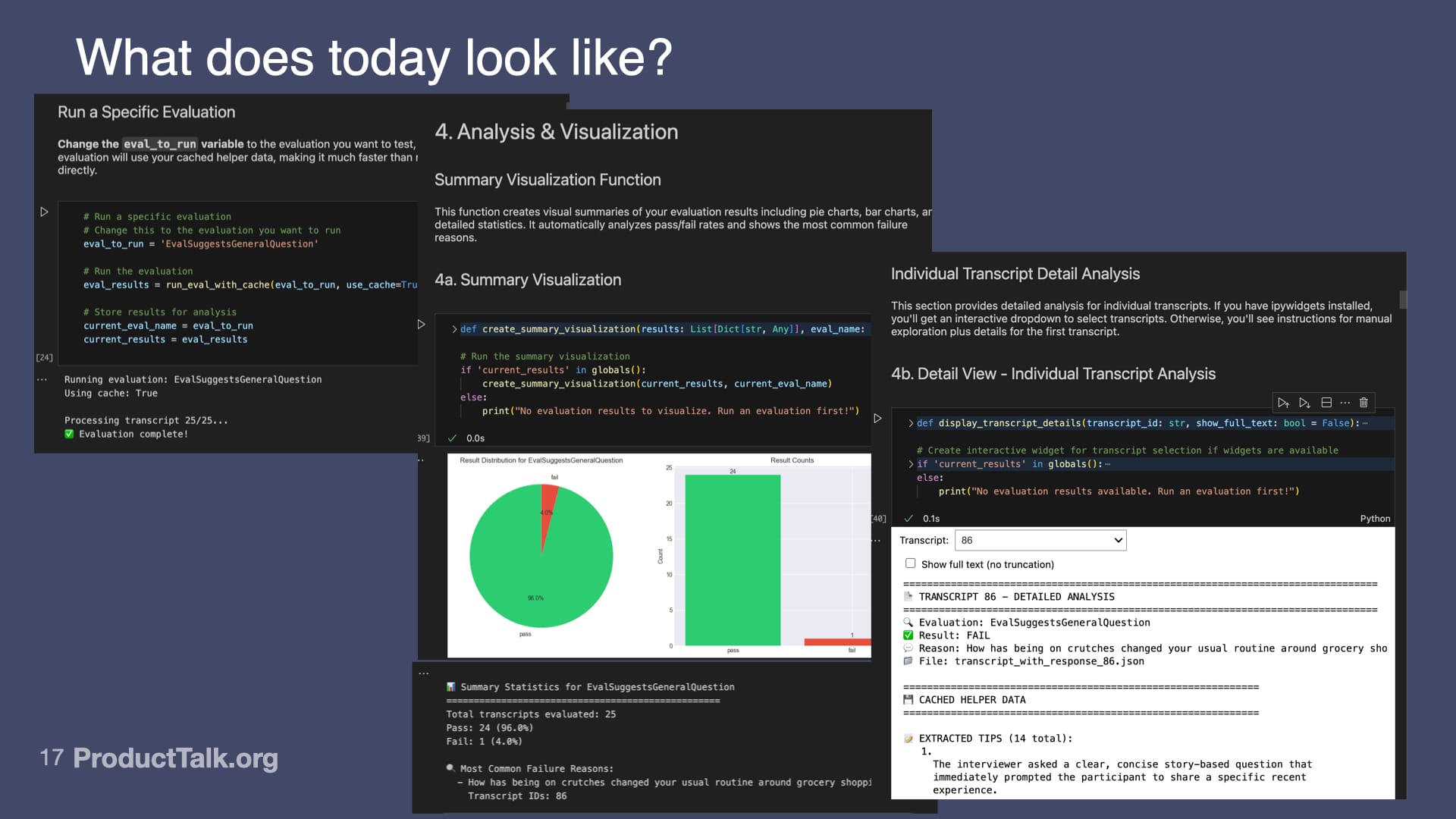
I set up a notebook where it doesn't have any of my eval code, but it can run my eval code from my dev environment. I basically set up a cell block that allows me to run a single eval or all my evals. Once an eval is written, I have all these visualization things.
I ran this yesterday. These are yesterday's results across my dev set, which currently—interview transcripts are big and running evals is expensive—so my dev set is only 25 transcripts. My test set is much bigger.
While I'm developing, I work on a small set. Then before I release, I run on a larger test set to make sure what I found in development holds on the larger set.
This I ran yesterday for my general evaluation: Is it suggesting a general question? You can see previously it was happening 4 out of 20 times. I have this down to 1 out of 25 times. This has gotten much better. That's because I can now measure it. I can make changes. I can see if my changes are improving it.
What's nice is in this notebook, I'm running the eval and visualizing the results right in the notebook. Today I'm doing this in VS Code. When I run into a problem with the notebook, I can just ask Claude Code: Help me fix this.
In my notebook, I have diagnostic tools. It's telling me 24 out of 25 traces did not have this error. One of them did. Down here, it tells me which trace had the error and what the LLM said, why the error occurred.
Then I have this tool that allows me to select that specific trace and actually look at all the output from my helpers, all the output from the LLM, so I can start to diagnose: Why is the LLM getting it wrong on this trace?
I'm doing all my data analysis in the notebook so that I can dig into the data and explore and figure out what I need to change to further reduce this error.
Building Better Annotation Tools
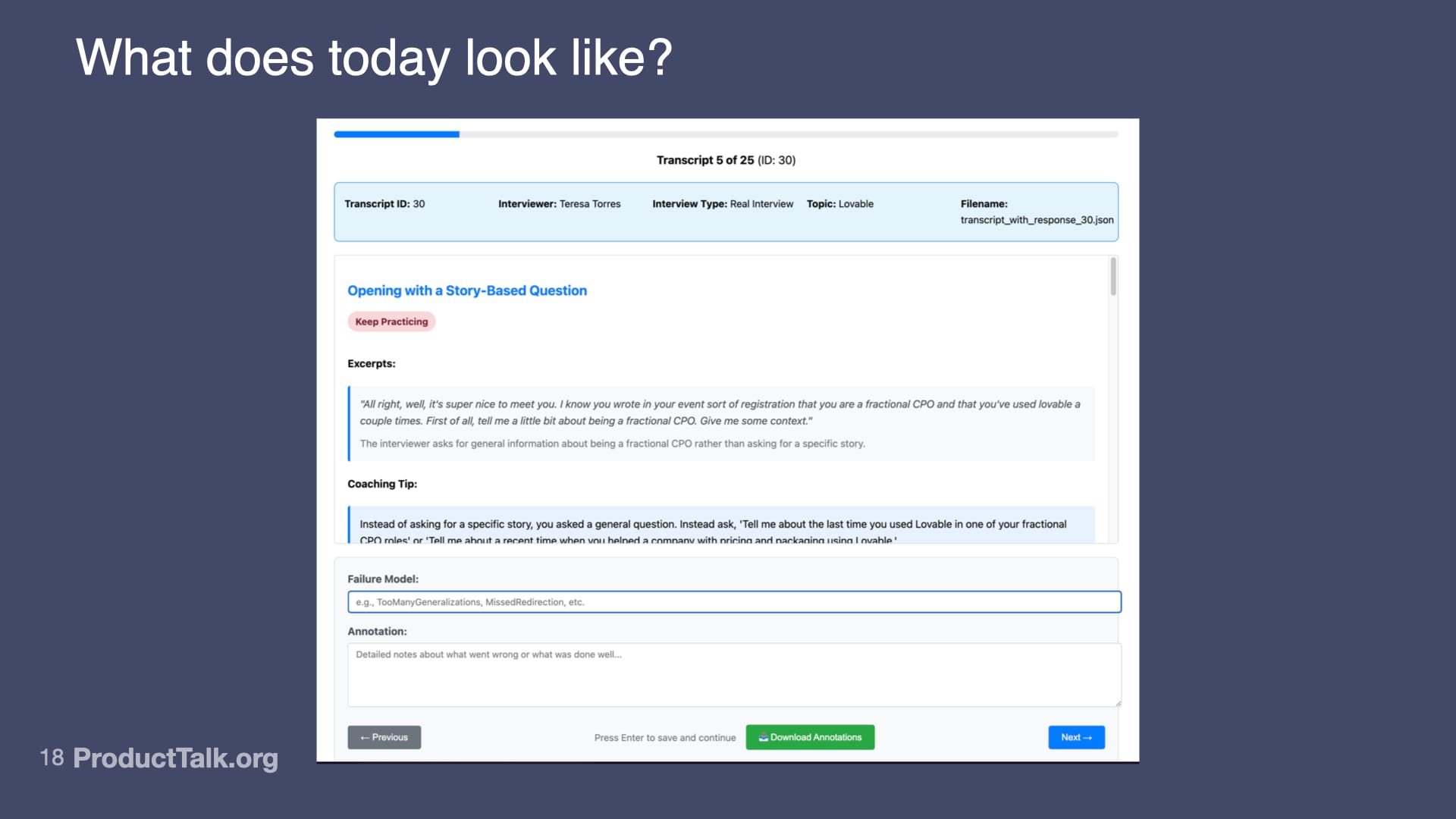
The other thing that's changed is I now build my own annotation tools. This is another thing that was really advocated for in the class. Claude Code actually built this tool. I literally just described to Claude Code what I need.
This is how I annotate today. I've got a progress bar at the top. You can see I'm in the middle of annotating 25 traces. It's showing the full LLM response. I have a box to annotate. I have a box to add failure modes. It supports shortcuts so I can quickly go through and annotate my traces.
I'm doing this so that I always have human labels to compare to my evals. I make sure that my evals stay aligned with my human judgment.
The Interview Coach Is Live
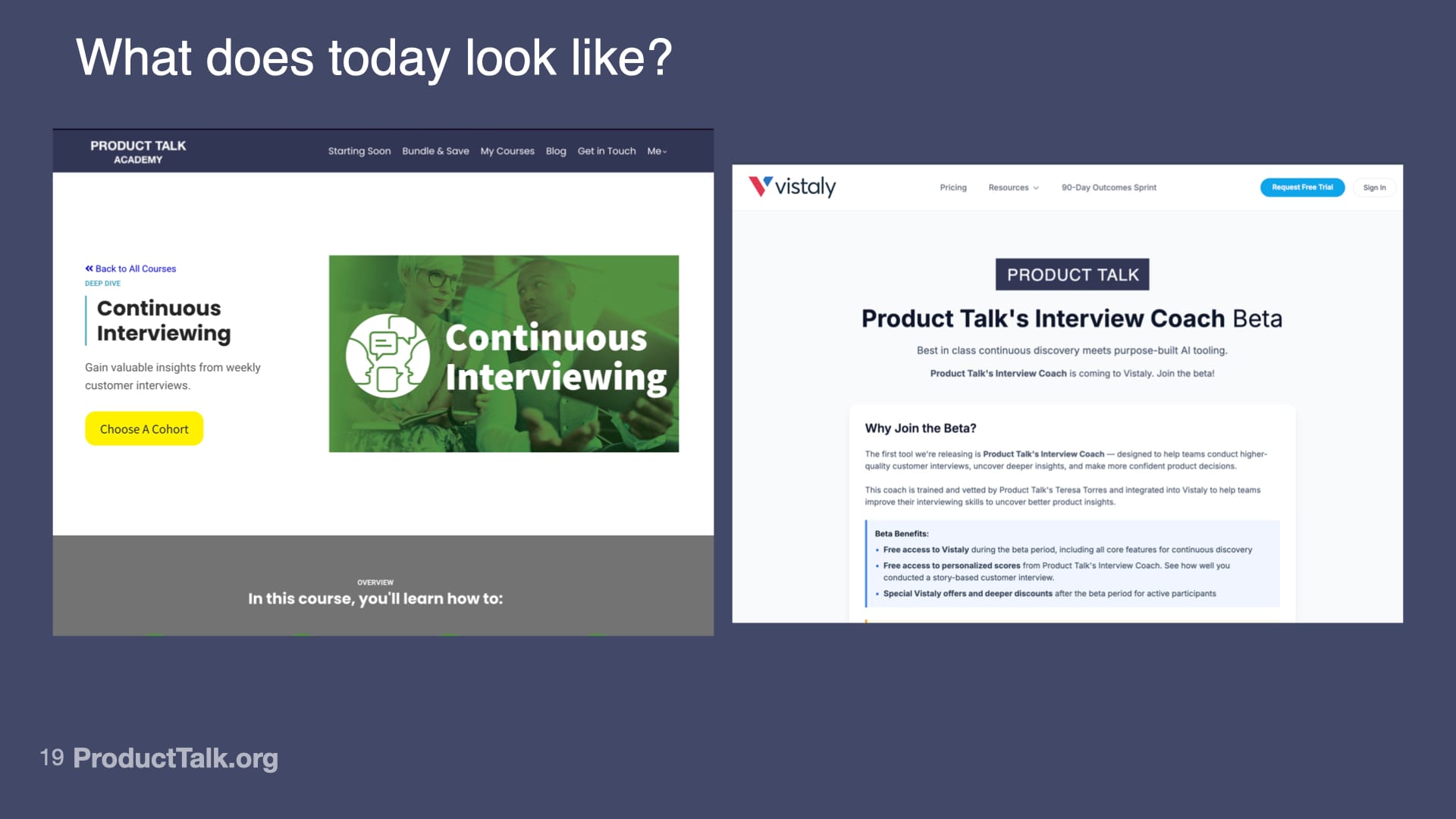
I know that was a whirlwind and it took longer than I thought. I'm really excited to share with you: the Interview Coach is live. We ran it in two cohorts in July. We got amazing feedback. Students kept asking for more access. This makes me so happy.
I have literally never built a full-production product before where I did all of the engineering. I'm very proud of this. I love it.
For those of you that are interested in getting access to the Interview Coach, we do have another cohort of Continuous Interviewing starting in September or you can get access through our on-demand Story-Based Customer Interviews course.
The other thing I will share I'm very excited about: I am partnering with Vistaly to bring the Interview Coach to Vistaly. If you're not familiar with Vistaly, it’s an opportunity solution tree tool. They do KPI trees and they're working on a really awesome feature to support interviews. As part of that, we're bringing the Interview Coach inside Vistaly. If you do want to play around and get access, this is how you can.
Key Learnings and Takeaways
Let me share some key takeaways for those who want to learn this.
Start small and build on what you know.
I was a total beginner five months ago. One of my favorite things about LLMs is that I can ask an LLM all my dumb questions. When I started in a Jupyter Notebook, I was like, "What's a Jupyter Notebook? How do I get started? Why do I care?" I barely knew markdown.
We now have a teacher that will handle all of our stupid questions. I just took one piece at a time. The reason why I started in Airtable—even though it's a less than optimal tool for long traces—is because I knew it and it was one less thing I had to learn.
If you're interested in learning this stuff, I strongly recommend the AI Evals class. That is a genuine endorsement. I was not paid for that (but you will get 35% off if you sign up using that link). Then I also recommend: Pick off one teeny-tiny piece and just try it and then pick off the next piece and then try it.
Along the same lines, I highly recommend starting with the simplest, dumbest eval because it might work. My code assertion eval that is just looking for keywords like "typically" and "usual" is really crude, but it works very effectively and is very aligned with my human labels.
Don’t neglect error analysis.
You have to do the error analysis to figure out what to measure in the first place. Anyone can go buy an eval tool off the shelf and it's going to measure a bunch of things. But what the eval tool is measuring will not necessarily be the problems that are coming up in your product.
Cross-functional collaboration is non-negotiable.
I mentioned earlier that one of the biggest questions I had was how in the world a product team is going to do this. We really will have to cross-functionally collaborate closer than we ever have, because it's probably going to be your engineer writing code, but your product manager and your designer are probably going to be involved in prompt design and even eval design.
Don’t forget: This is continuous work.
I think when we build AI products, we have to commit to evolving them continuously over time because they will drift. If you care about quality, it will require a continuous investment.
We're living in a time where we can do way more than we ever thought was possible. If you are interested, I encourage you to literally just get your hands dirty and start playing.
Want to make sure you catch the next installment in this series as soon as it goes live? Subscribe to Product Talk so you never miss a post.
Comments ()