AI Changes Everything (And Nothing At All)

Every product team is wrestling with the rapid change brought on by generative AI. It's impacting our roadmaps and how we do our jobs.
But not everything is changing. Many of the fundamentals stay exactly the same.
Last week, I delivered this talk as part of The Future of Product Management Summit hosted by Pragmatic Institute. I want to share it with you.
I don't have a video of the talk, but I'm sharing the slides and my script.
Full Talk with Slides
Welcome, everyone! I'm Teresa Torres, and I'm excited to talk with you today about AI and product management.
The title of my talk is "AI Changes Everything (And Nothing At All)"—and I know that sounds contradictory. But over the next 30 minutes, I hope to show you why both are true.
Let me start with a quick foundation. How many of you have used ChatGPT or Claude or another large language model?
[Everyone in the audience had used AI, but only some had integrated AI into their products.]
Great. So you know what LLMs can do. But do you understand HOW they work?
Understanding How LLMs Work

At their core, large language models predict the next token. That's it.
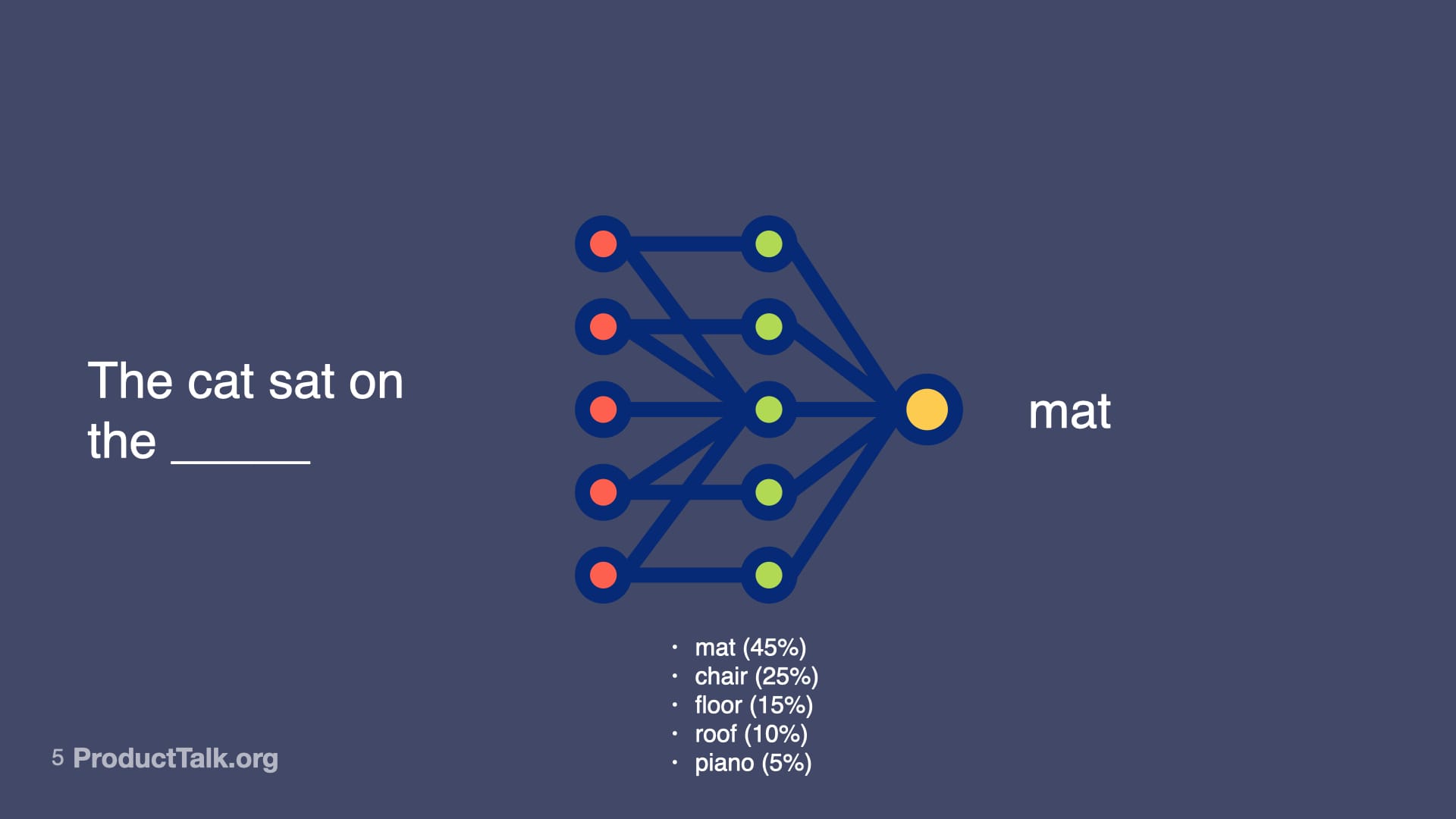
Look at this sentence: "The cat sat on the ____"
The model looks at all the text it's been trained on and calculates probabilities. Mat is most likely. Chair is pretty likely. Floor, roof, piano—all possible, just less probable.
Most of the time it picks the most probable response. And it does that over and over again.

Now some people see this technology and think, "AGI is around the corner! This changes everything!"
Others look at the same technology and say, "This is overhyped. It makes too many mistakes."
Which is it?
Well, the key insight is understanding how those predictions get made.
LLMs are trained on massive amounts of data from across the internet, books, code repositories, and scientific papers. They've encoded patterns from much of human knowledge into a neural network.
And this turns out to be really powerful.
When you give an LLM a prompt, it runs through this neural network—billions of parameters making calculations—to predict the most likely next word, then the next, then the next.
That neural net represents not just facts, but relationships, patterns, context—and some might even argue reasoning capabilities—that all influence the probabilities of different outputs.

So LLMs don't just predict the next token. They predict the next token by drawing upon a vast amount of knowledge.
And this turns out to be incredibly powerful. They can write code, translate documents, edit videos, and even clone our voices.
LLMs are transformational.

And yet, AI makes silly mistakes. The kind that make you wonder how it could be so smart and so dumb at the same time.
No matter how hard I tried, I could not get ChatGPT-5 to fix the closing quote on this image.
And it took 12 seconds of thinking (that's running computations through its neural network) to figure out that I asked for a meeting summary but didn't include any meeting notes.
Why do LLMs make these mistakes?
Well, it's because all the LLM is doing is predicting the next token based on patterns. And sometimes those predictions are wrong. And when it's wrong, it can be confidently wrong.
So what do we do?
Leveraging the Power of LLMs While Reducing the Mistakes

If we want to get good at building with AI, we need to learn how to take advantage of the power while reducing the mistakes.
So let's explore how to do exactly that.
We have to start by learning some new skills. And the first skill we are going to introduce is prompt engineering.
1. Prompt Engineering
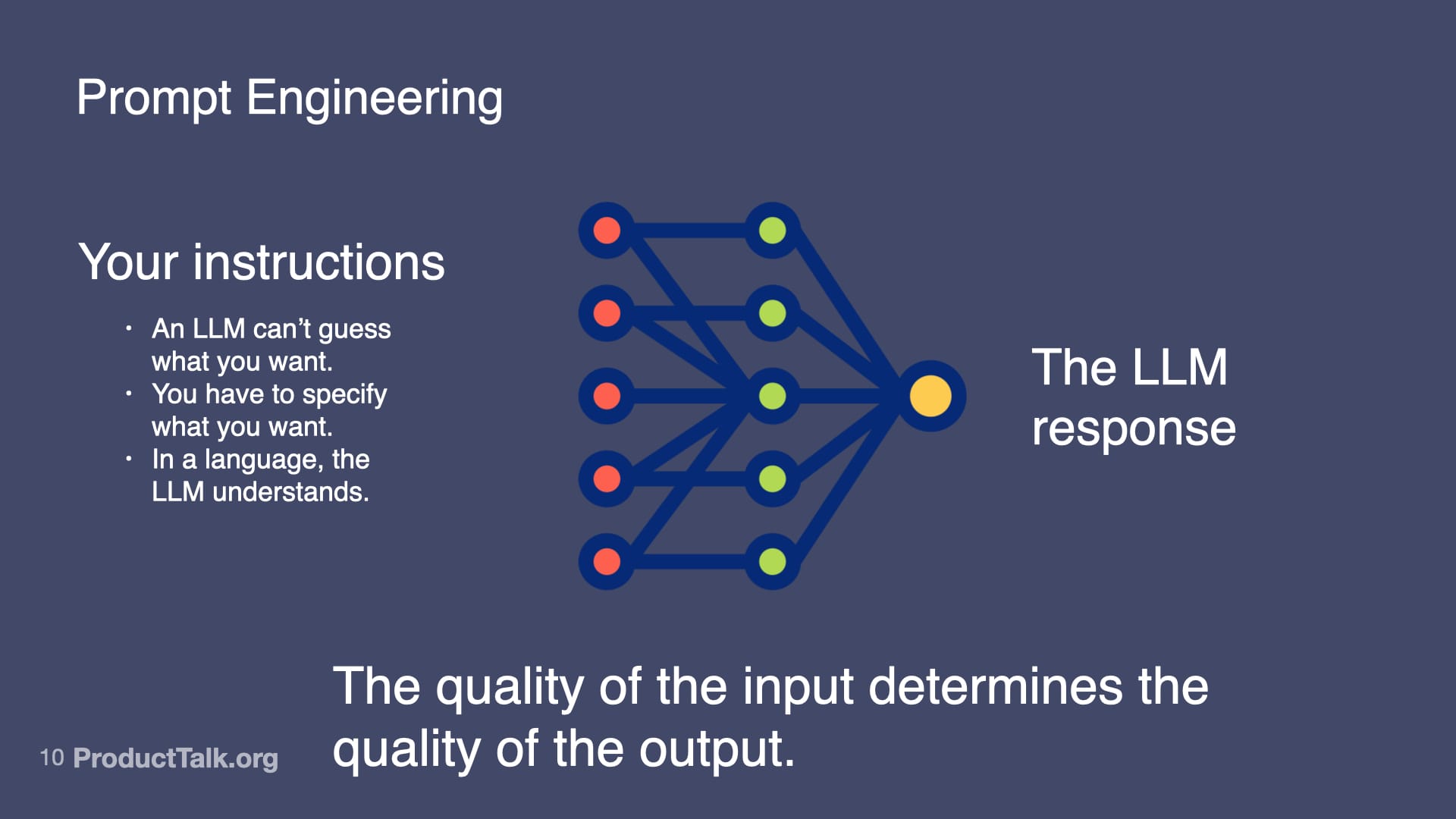
With LLMs, the quality of the input determines the quality of the output.
An LLM can't guess what you want. You have to specify what you want in a language the LLM understands.
Now, when YOU use ChatGPT, you can have a conversation. You can refine what you're asking for over multiple turns.
But when we build AI features into our products, we get one shot. Our customers aren't going to have patience for a back-and-forth.
Let me show you what I mean with an example.
Suppose you get out of a meeting and you want ChatGPT to summarize the notes. So you upload a transcript and you ask: "Summarize this meeting."
But you weren't very specific. And so ChatGPT doesn't give you what you want.
That's okay, you can try again.
You might follow up with: "What are my action items?"
And so ChatGPT gives you a list of all action items. But you aren't sure who committed to which ones. So you might follow up again: "Who said what?"
Now this is some pretty sloppy prompting. But it's okay. We can go back and forth with ChatGPT until we get exactly what we want.
But now imagine you want to add a feature to your platform that automatically summarizes meeting notes for your customers.
Now suddenly, how you prompt the LLM matters a lot. You don't want your customer to have to go back and forth with your tool. You just want it to work.
This is where prompt engineering comes in. We have to design a prompt that will work reliably thousands of times on a wide variety of meeting types. We have to tell the LLM exactly what we want and how to do it.
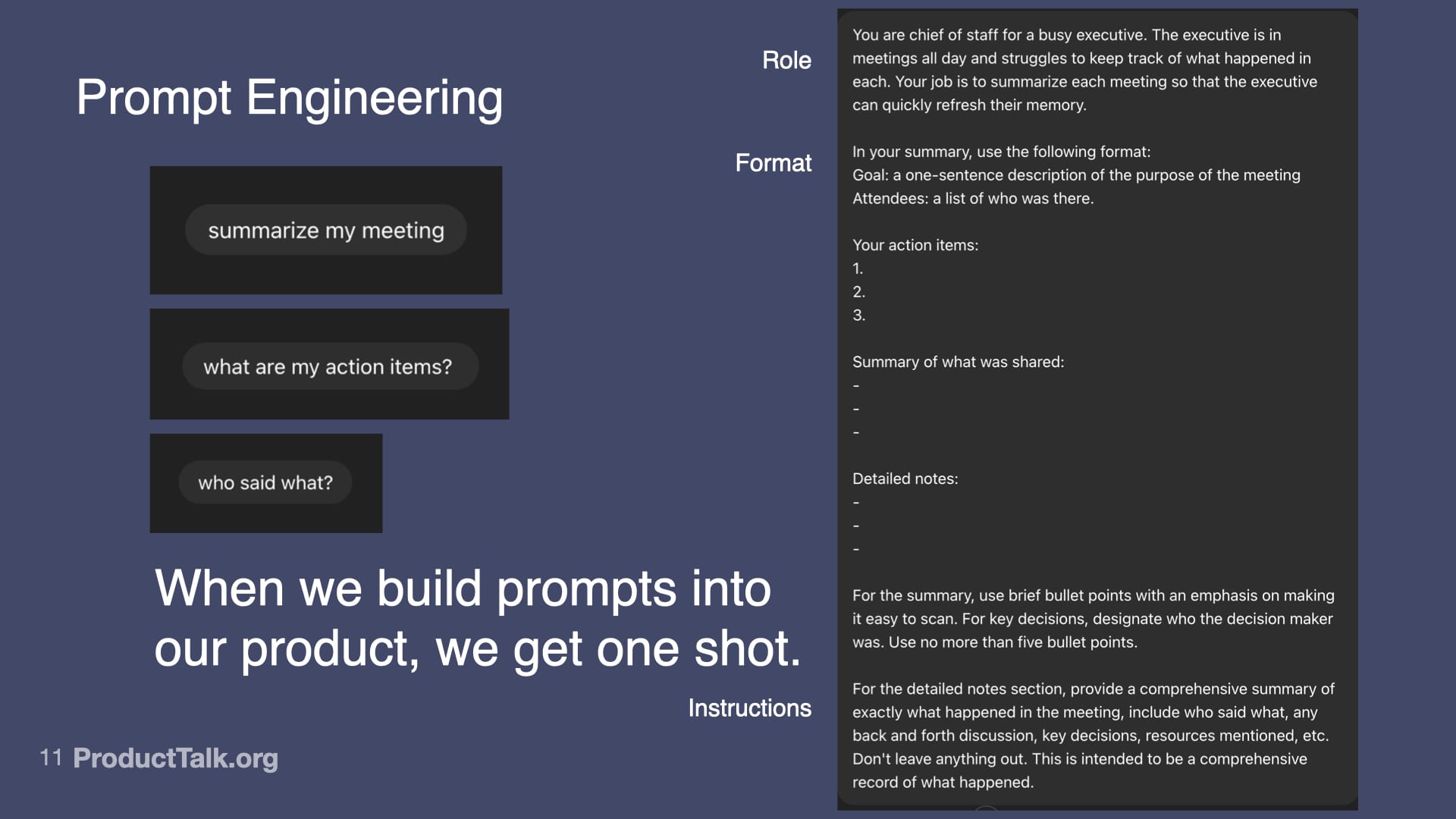
Look at what a production-ready prompt looks like:
- We give the LLM a role: "You are a chief of staff for a busy executive..."
- We specify the exact format we want the output in: a list of action items.
- We provide detailed instructions about what to include and how to structure it.
This is prompt engineering. It's like writing a really good product spec—but for an AI.
The next skill we need to learn is context engineering.
2. Context Engineering

LLMs know a lot, but not everything.
Imagine one of the meeting takeaways is: "Send the pipeline report to John by Friday."
- When is Friday? (tomorrow or next Friday?)
- Which John?
- What is the pipeline report?
Wouldn't it be nice if our meeting summarizer could enrich our notes?
There's only one problem. The LLM is missing some important context.
- It doesn't know today's date.
- It doesn't know the roles of everyone in the room and so can't determine which John we're referring to.
- It doesn't know what types of reports we use.
- It doesn't know specifically what the pipeline report is.
As product managers, our job is to figure out what context the AI needs and how to provide it.
So we might want to give the LLM access to our employee database, our report system, our employees' calendars, and much more.
But here's the challenge: You can't just dump everything into the context.
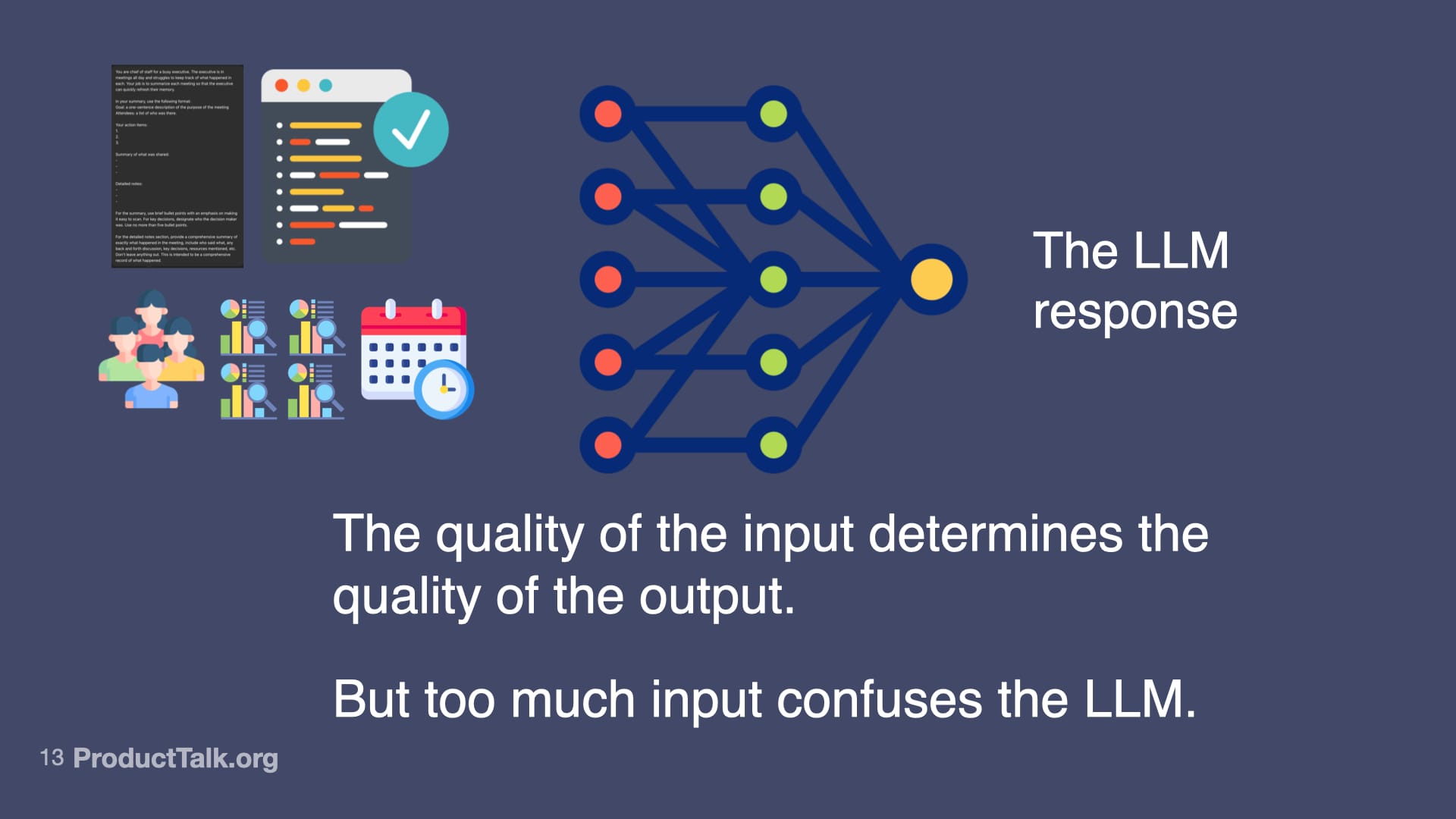
Remember, the quality of the input determines the quality of the output.
If you give the LLM too much information, it gets confused. It's like trying to have a conversation in a crowded room—it gets distracted by the noise.
The key to context engineering is we want to add only the context the LLM needs to do the task at hand and nothing more.
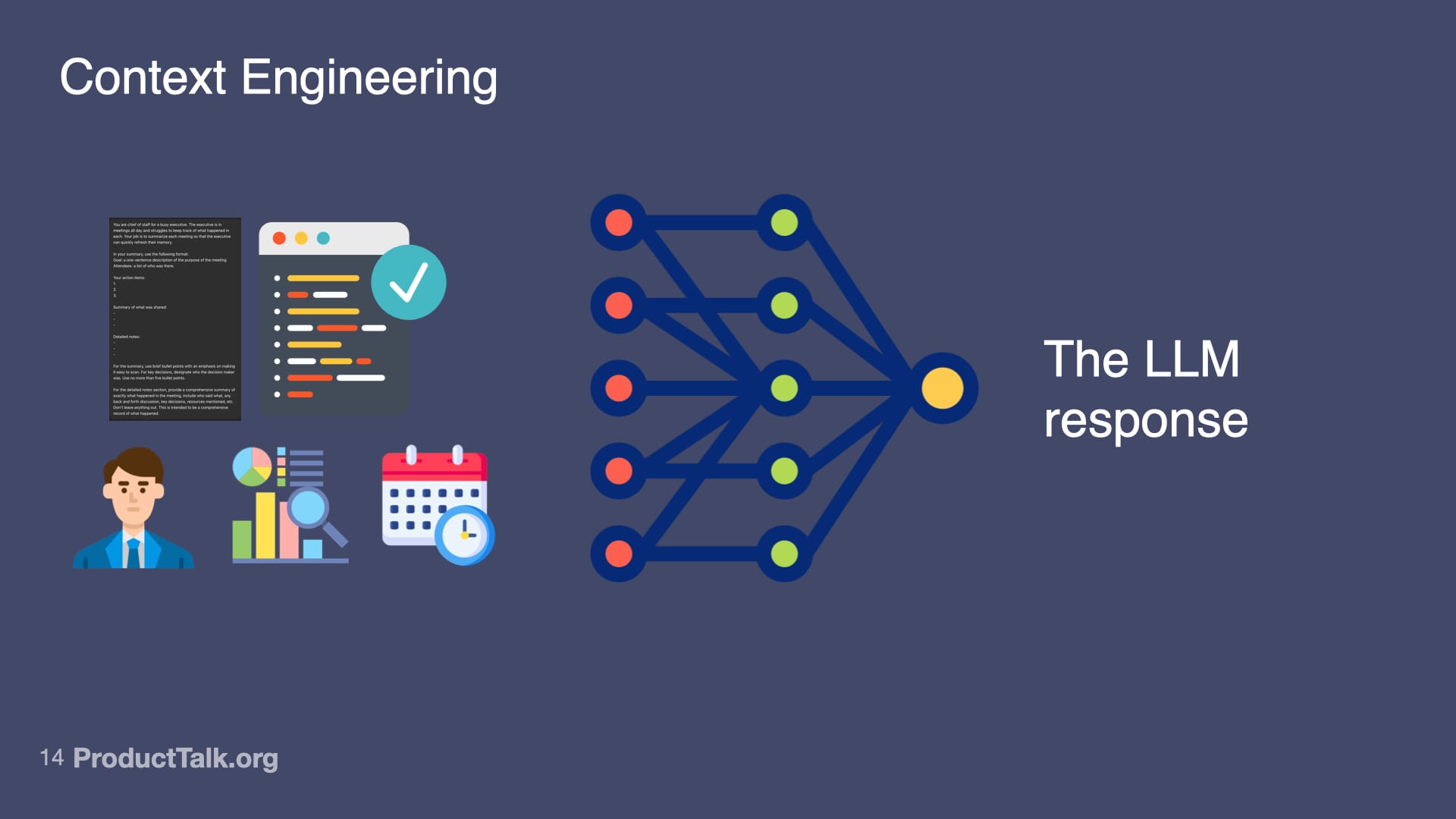
So it doesn't need the entire employee database. It just needs to know the roles of the people in the room.
It doesn't need to know about all of our reports. It just needs to know what the pipeline report is.
This is where techniques like RAG (Retrieval Augmented Generation) come in. You search for just the relevant context and include that in your prompt.
The next skill is orchestration.
3. Orchestration

LLMs are better at simpler tasks.
If you try to do everything in one prompt—identify action items, summarize the meeting, categorize by urgency, match to owners, check for clarity—the quality goes down.
But if you break it into steps, each focused on one thing, the quality goes up.
This is orchestration—designing a workflow of multiple LLM calls that work together.
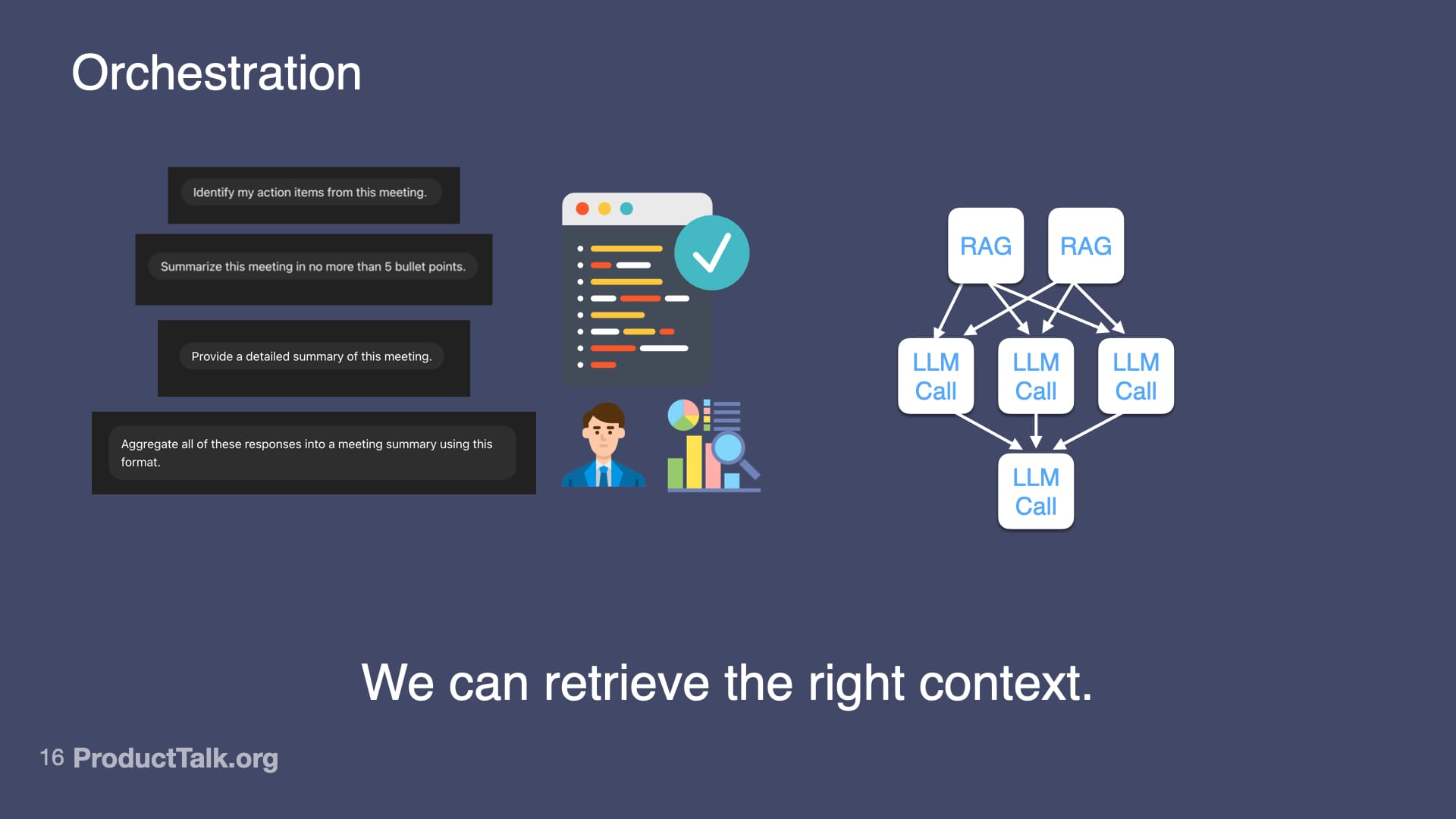
With orchestration, we can add RAG steps to retrieve the right context and only send each task the context it needs.
For example:
- First call: Identify action items (just needs the transcript)
- Second call: Categorize by urgency (needs the action items + project context)
- Third call: Match to owners (needs action items + team directory)
- Fourth call: Generate calendar events (needs action items + calendar API access)
Each step is simple. But together, they create something sophisticated.
As product managers, this is process design. You're mapping out the workflow the AI needs to follow.
The next skill we need to learn is evals.
4. Evaluation (Evals)
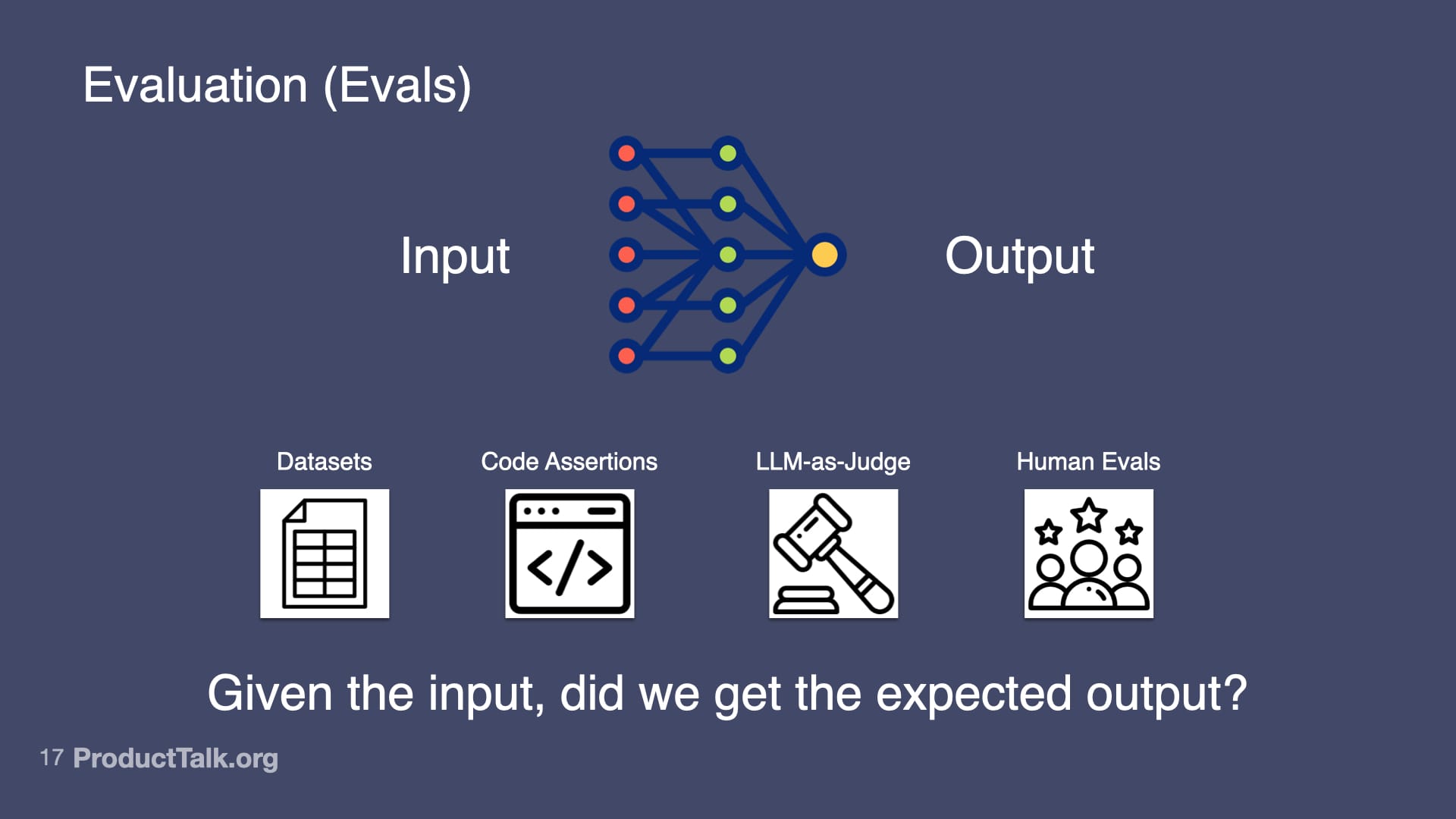
Otherwise known as: Is my AI product any good?
At the heart of evals is this fundamental question: Given the input, did we get the expected output?
And there are different ways to answer that question:
- Datasets: Collect 20–100 examples of real inputs and the outputs you expect. Run your prompt against all of them. Measure success rate.
- Code Assertions: Write rules that the output MUST follow. "Every action item must have a task, owner, and deadline." If the output doesn't match, fail the test.
- LLM-as-Judge: Have another AI evaluate whether the output is good. "Is each item in this summary in the meeting transcript? Yes or no."
- Human Evals: Do they need to edit the meeting summary?
Start with simple evals and get more sophisticated as you need them.
Why Learning the New AI Skills Isn't Enough
You can master prompt engineering. You can nail context engineering. You can orchestrate beautiful workflows. You can have rock-solid evals.

You can learn all these new AI skills. And still build the wrong product.

Why? Because you chose the wrong problem to solve. Who needs yet another meeting summarizer?
This is the trap with AI. The technology makes it so easy to build that we often forget to ask whether we should build it.
This is where the fundamentals come in.
1. Discovery Matters More Than Ever
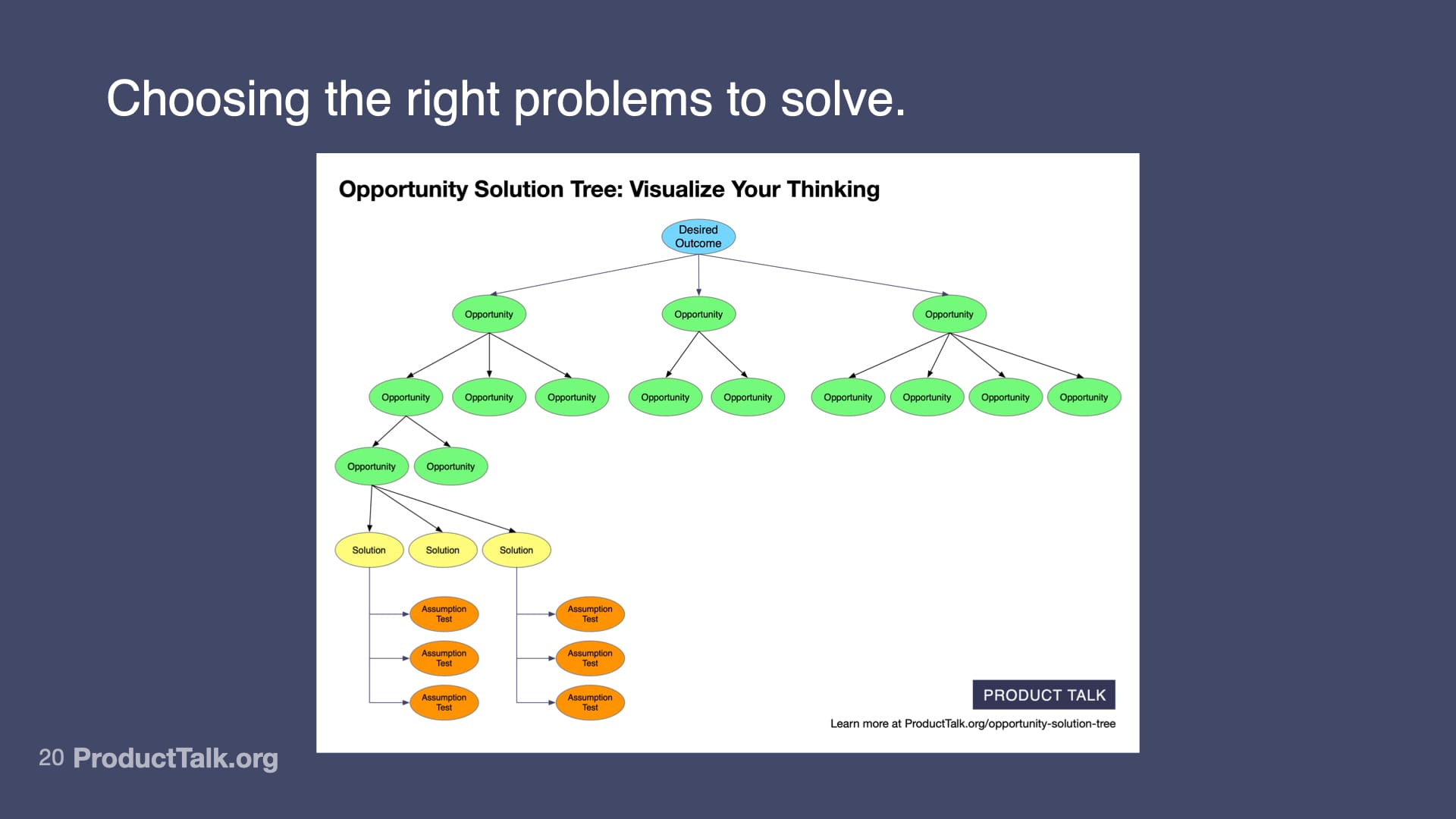
Before you write your first prompt, you need to do discovery.
- You need to be clear on what impact you are trying to have and set a clear outcome.
- You need to talk to your customers and make sure you understand their needs. You need to choose the right opportunity to start with.
- You need to explore multiple solutions and use assumption testing to help you choose the right one.
AI makes it easier to jump to solutions. The technology is so exciting, we skip straight to "What can we build?" instead of asking "What should we build?"
Don't skip discovery just because AI makes building faster.
The second fundamental: Prototype, test, and build iteratively.
2. Prototype, Test, and Build Iteratively
With AI products, this fundamental becomes even more important. It's easy to get to a good demo. It's hard to get to a high-quality, production-ready product.
Let me show you what this looks like with a real example.
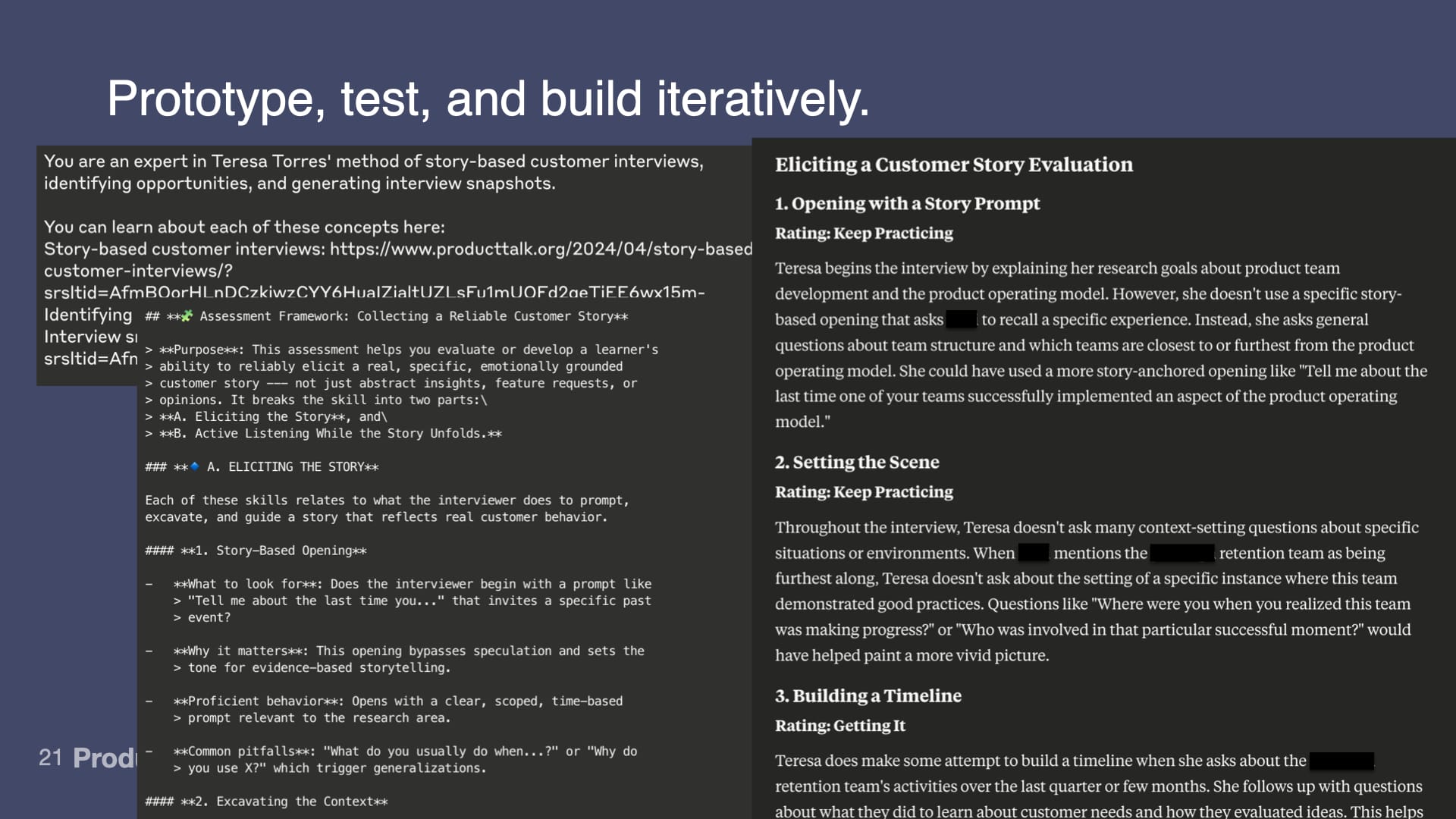
I built an AI Interview Coach for my Customer Interview course. Students upload interview transcripts, and the AI gives them feedback on their interviewing technique.
But I didn't start by building a product. I started by testing whether this was even possible.
I went to Claude—just the web interface—and I started pasting in interview transcripts and asking it to evaluate them.
Could Claude give useful feedback? What prompt would I need? What instructions? What format?
I spent a few hours just experimenting in a Project on Claude. Tweaking prompts. Testing different approaches. Getting a feel for what worked.
Only once I had confidence that this had promise did I ask: How do I deploy this to students?
My first thought was I needed a way for students to submit their transcripts. And I needed a way to limit access to just my students.
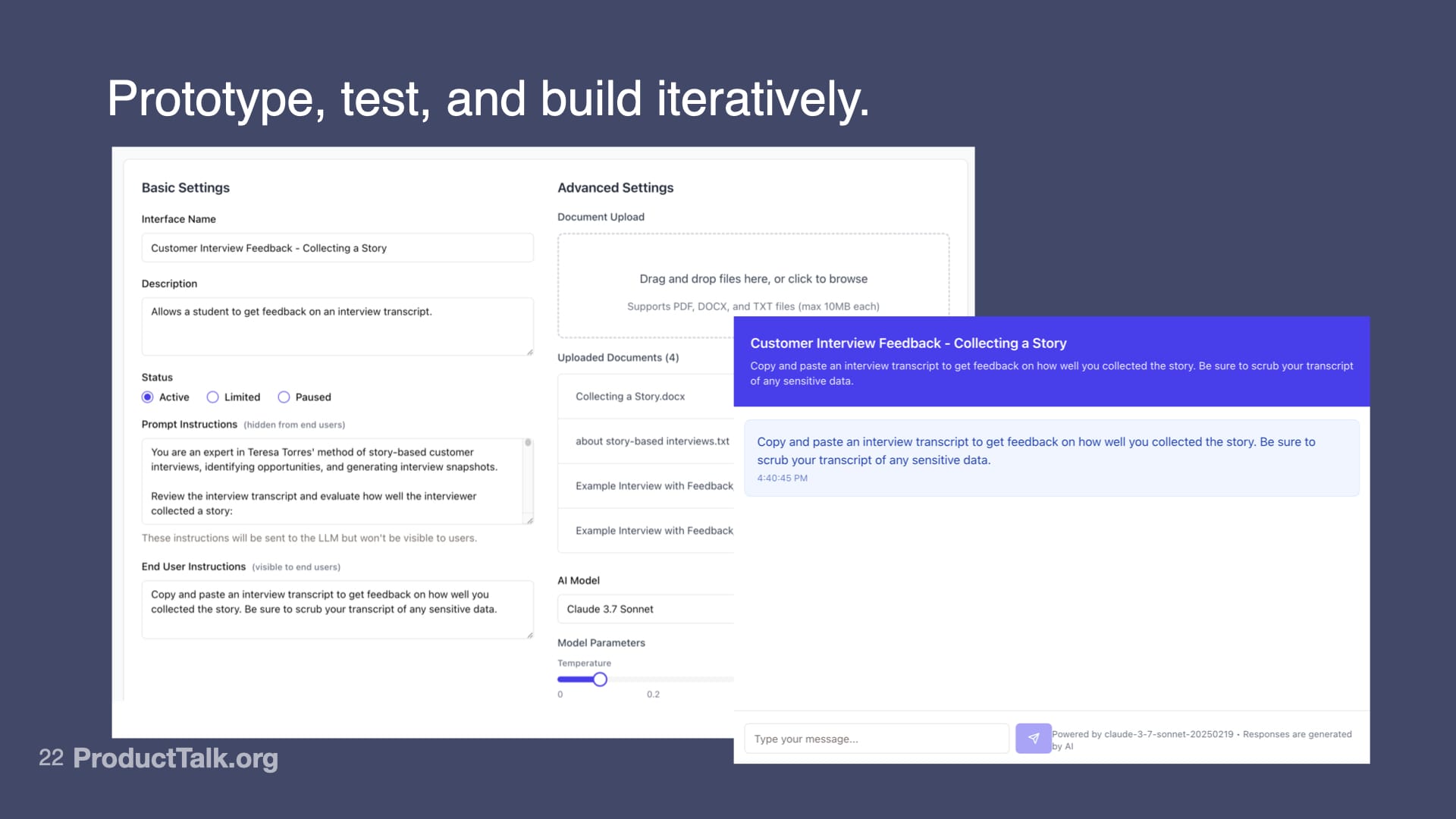
I decided to use Replit to build a custom chat interface that I could embed right into my course platform.
But when I launched it to a few students, I realized a chat interface was all wrong. I built the Coach to give feedback on a transcript. It wasn't good at answering students' questions about that feedback.
So I threw that out and tried something different.
I decided to use my course platform's homework assignment feature.

Students upload their transcript. The system processes it. They get detailed feedback. Done.
No chat. No back-and-forth. Just feedback.
So I built that using a Zapier workflow. Student submits the assignment, Zapier picks it up, calls Claude's API, formats the feedback, delivers it back.
It worked great! For a while.
Then I started hitting issues. Zapier's error handling wasn't robust enough. Feedback would get stuck in an eight-hour queue.
So I had to rebuild it again—this time as an AWS Step Function. More reliable, better error handling, proper retry logic.

Each iteration, I was testing different assumptions:
Iteration 1 (Claude): Can AI even do this? What makes good feedback?
Iteration 2 (Replit chat): How do I deploy it? What interface do students need? How should they interact with it?
Iteration 3 (Zapier): Can I integrate this into my existing course platform? What's the simplest automation?
Iteration 4 (Step Functions): How do I make this reliable at scale? What happens when things go wrong?
Notice: I didn't know any of this upfront. I learned by building, shipping, and watching how students used it.
This is how you de-risk AI features. Not by building everything upfront, but by testing assumptions step by step.
The third fundamental is ethical data practices.
3. Ethical Data Practices

With AI products, you need to inspect traces to debug problems and improve performance. A trace is a detailed record of an AI interaction—the user input, system prompts, tool calls, LLM responses.
For my Interview Coach, a trace includes:
- The interview transcript the student uploaded
- My system prompts about how to evaluate interviews
- The AI's feedback to the student
To make the product better, I need to look at traces where things went wrong. But those traces contain student data. Sometimes sensitive student data.
Here's where a lot of AI products get it wrong. They collect everything by default. They inspect traces without explicit permission. They optimize for their learning instead of user privacy.
Don't do this.
In my product, students have to explicitly grant permission for me to review their transcript. The consent is clear. It's specific.
If they say no, I don't get to see their data. Full stop. Even if it means I can't debug their issue as well.
This is harder. It means I can't just look at every trace. It means I have to use synthetic data for testing. It means I have to get creative about how I improve the product.
But it's the right thing to do. And increasingly, it's going to be required by regulation.
Build privacy into your architecture from day one. Don't bolt it on later.
Everything Changes (And Nothing Changes)

So let's recap where we've been.
There are some new skills we need to learn.
- You need to learn prompt engineering—how to write instructions that get the output you want the first time.
- You need to learn context engineering—how to give the LLM exactly the information it needs, nothing more, nothing less.
- You need to learn orchestration—how to break complex tasks into simpler steps that LLMs handle better.
- You need to learn evals—how to systematically measure whether your AI is working.
These are new skills. They matter. You should learn them.
But we can't forget about the fundamental skills we've always relied upon.
- You still need to solve the right customer problems. AI doesn't change the need for discovery.
- You still need to prototype, test, and build iteratively.
- You still need to employ ethical data practices.
Here's my point: Yes, you need to learn new skills. But those new skills only matter if you're building the right thing in the first place.
The teams that win with AI will master both. The new technical skills and the timeless product fundamentals.

If you want to go deeper on any of this:
Product Talk is where I write about product discovery, opportunity solution trees, continuous interviewing—all the fundamentals we talked about today. I'm also writing about my own experience building AI products.
And Just Now Possible is my new podcast all about building with AI. Every week I interview product teams who are building real AI products. They share what's working, what's not, and what they're learning.
You'll hear stories that illustrate everything we talked about today—teams mastering the new skills while keeping the fundamentals strong.
Thank you!
Audio Version
The audio version is only available for paid subscribers.