Stop Repeating Yourself: Give Claude Code a Memory
"Can you critique the landing page for my new Story-Based Customer Interviews course?"
I used to waste hours trying to get ChatGPT or Claude to adequately critique my work. I'd get frustrated by the generic feedback, the poor writing, and the suggestions that just wouldn't work for my audience or my products.
But not anymore. Not only does Claude critique my work; it also helps me produce the work.
It helps me generate marketing copy—in my voice! It helps me write blog posts. It knows what search terms are relevant to my business and helps me optimize my articles for SEO and now AEO. It helps me with competitive research, academic research, and discovery research. And it does all of this with little prompting from me.
I don't have to upload files to a web-based project. I don't have to save and manage detailed prompts. I don't have to keep repeating myself. I just ask for help and Claude knows exactly what to do.
How did I get here?
I learned how to give Claude Code a memory. Claude knows who my target customer is, the key value propositions I focus on, the specific opportunities each product addresses, my revenue model, my marketing channels, and so much more.
So now when I ask Claude for help, it has all the right context it needs to be an expert helper. I get high-quality output tailored to my audience that works for my products and services. Every time.
And I don't have to keep giving Claude this context over and over again. Instead, it just remembers.
Today, I'm going to show you how I gave Claude a memory. It relies on Claude Code (which requires a Pro subscription), but I promise it will be worth it. If you are new to Claude Code, be sure to start with: Claude Code: What It Is, How It's Different, and Why Non-Technical People Should Use It.
This article is the second in a series. Be sure to check out the other articles:
- Claude Code: What It Is, How It's Different, and Why Non-Technical People Should Use It
- Stop Repeating Yourself: Give Claude Code a Memory
- How to Use Claude Code Safely: A Non-Technical Guide to Managing Risk
- How to Choose Which Tasks to Automate with AI (+50 Real Examples)
- How to Build AI Workflows with Claude Code (Even If You're Not Technical)
- How to Use Claude Code: A Guide to Slash Commands, Agents, Skills, and Plugins
- Context Rot: Why AI Gets Worse the Longer You Chat (And How to Fix It)
I have not received any compensation from Anthropic for writing this series. And you can trust that if that ever changes, I will disclose it. This is not only required by the FTC here in the US, I strongly believe it is the right thing to do. You can count on me to do so.
Every Conversation Starts from Scratch
The challenge with large language models (LLMs) is that by default every conversation starts from scratch. The LLM only knows what you tell it—in that specific conversation.
There are some exceptions. ChatGPT can remember some things about you. Claude can search your past conversations. But for the most part, every conversation wipes the slate clean.
If you, like me, were working on a new landing page, you'd have to upload information about your target customer, the product itself, and the primary and secondary value propositions. You'd have to upload the questions and answers to add to the FAQ. And the testimonials and logos for social proof.
And for my web-based ChatGPT Projects or Claude Project fans, yes you can upload all of this information to a Project and use it across multiple chats. But what happens when you work on the next landing page?
Imagine the next one is for the same target customer but for a different product with a different value proposition. Do you start a new Project? Or do you just add to your existing Project? The former is tedious. The latter muddies the context window (which leads to deteriorating output quality).
This is a real challenge. But I have good news for you. You can solve this problem with Claude Code. You simply have to give it memory.
What Memory Unlocks
You've already learned in our Claude Code guide that Claude Code can read the files on your local machine. This is an understated superpower. It means we can use files to create a memory for Claude that will work across all your chat sessions and across any Project.
Files can be mixed and matched. So you can give Claude exactly what it needs for the task at hand—and nothing more. When you are working on your first landing page, you can reference your target customer and the relevant product. When you are working on your second landing page, you can simply reference the same target customer, but reference the new product.
When you give Claude (or any LLM) the exact right context, you get higher quality output. LLMs benefit from more context, but only if it's relevant to the task at hand.
So to help with your landing page, Claude needs to know about the current product and maybe related products (so it can help differentiate the products), but it doesn't need to know about unrelated products. If we structure our memory files properly, we can give Claude exactly what it needs and nothing more.
When we do this, Claude shifts from being an intern who can tackle one-off tasks to being a trusted advisor and a talented employee who can help you get work done. Claude doesn't have to guess at the value proposition for your product—you've already told it. It already knows how to write in your voice because it has access to your writing guide and plenty of writing samples. It doesn't have to ask who teaches which course. It just knows.
Giving Claude a memory takes a little bit of setup. But it's an investment that compounds over time. You set it up once and can use it forever. You only need to tell it about your target customer once and Claude will always know about it.
If your target customer changes, you simply need to update your text file. Same with your products—you can easily add and remove information as your products evolve. Odds are much of this information already lives in your file system. It's just a matter of making it easy for Claude to use.
And because files live on your local machine, you own them. You can share them across devices. There's no device or vendor lock-in. You decide when and who to share them with. You might work with Claude on one project and ChatGPT (via Codex) on another project. Both can rely on the same memory system.
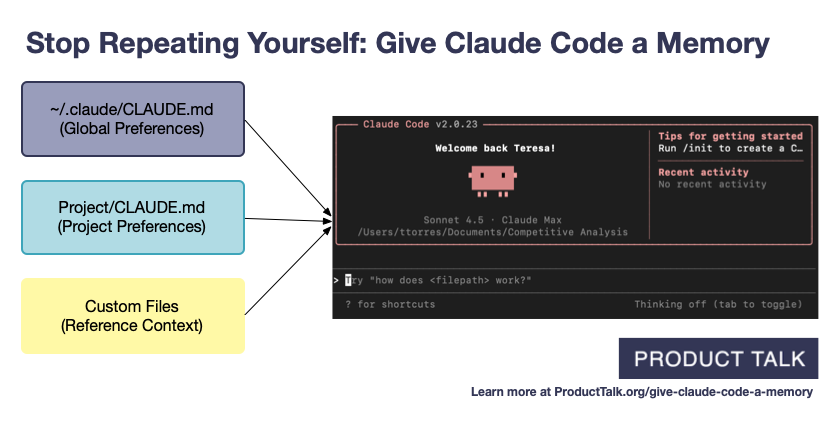
Design a Three-Layer Memory System
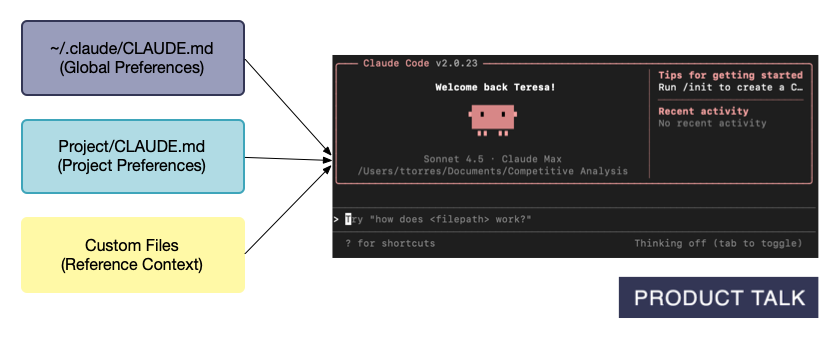
So how do you actually structure Claude's memory? You need three distinct layers.
Claude Code already encourages you to create two types of context files: global preferences and Project-specific instructions. But there's a third layer that most people miss—and it's where the real power lives.
Layer 1: Global Preferences (Always on)
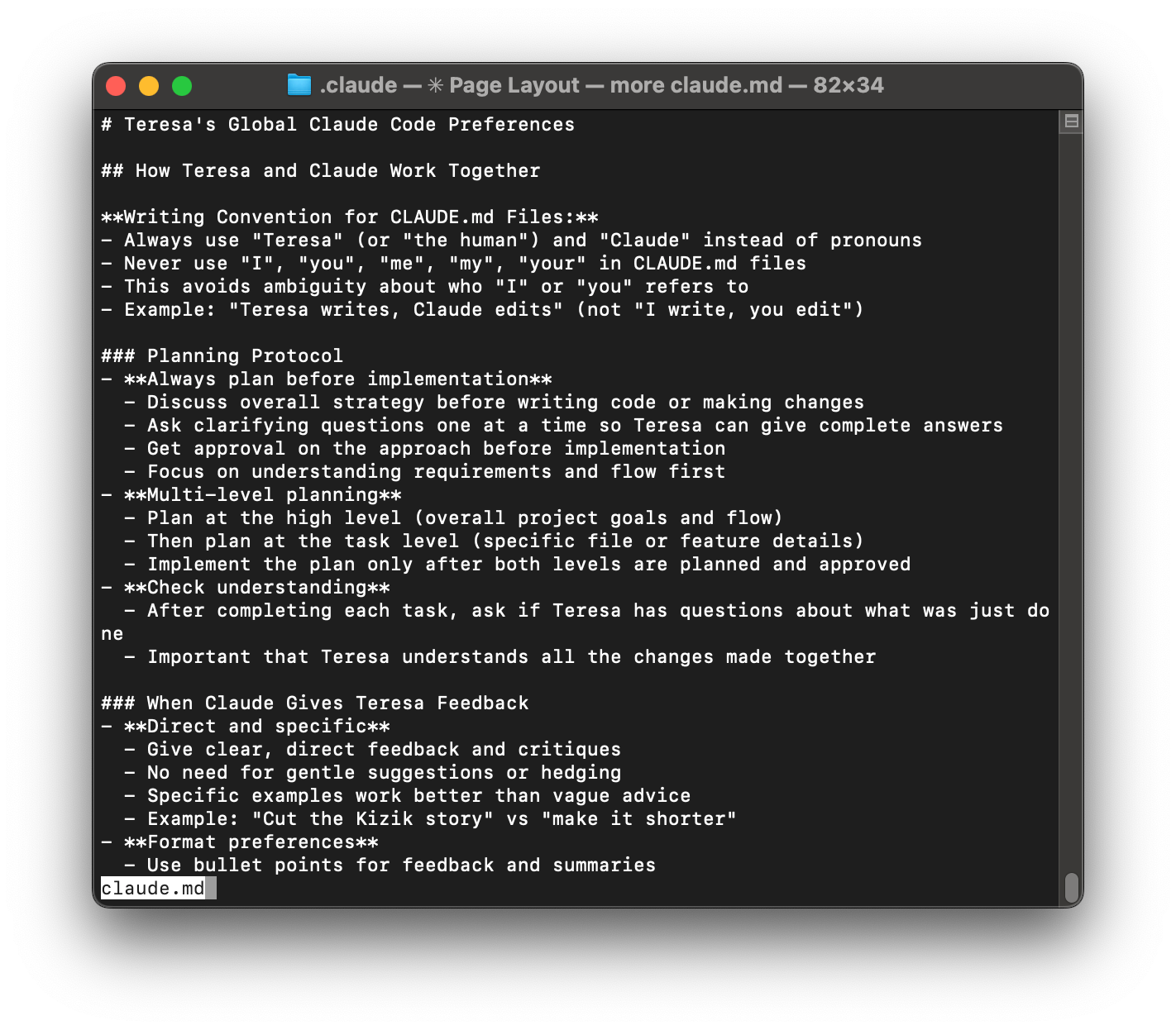
The first time you launch Claude Code, it encourages you to create a CLAUDE.md file in your root directory (~/.claude/CLAUDE.md).
This is where you want to store your global preferences. Think about it as your instructions for Claude about how you like to work together, no matter what type of project you are working on.
Mine includes things like:
- Always create a plan for me to review before you start any work
- Give me direct feedback (no hedging, no gentle suggestions)
- Use bullet points for summaries
- Ask clarifying questions one at a time so I can give complete answers
- No emojis unless I explicitly ask for them
Claude Code automatically loads this file at the start of every session, so I never have to explain my preferences again.
Layer 2: Project-Specific Instructions
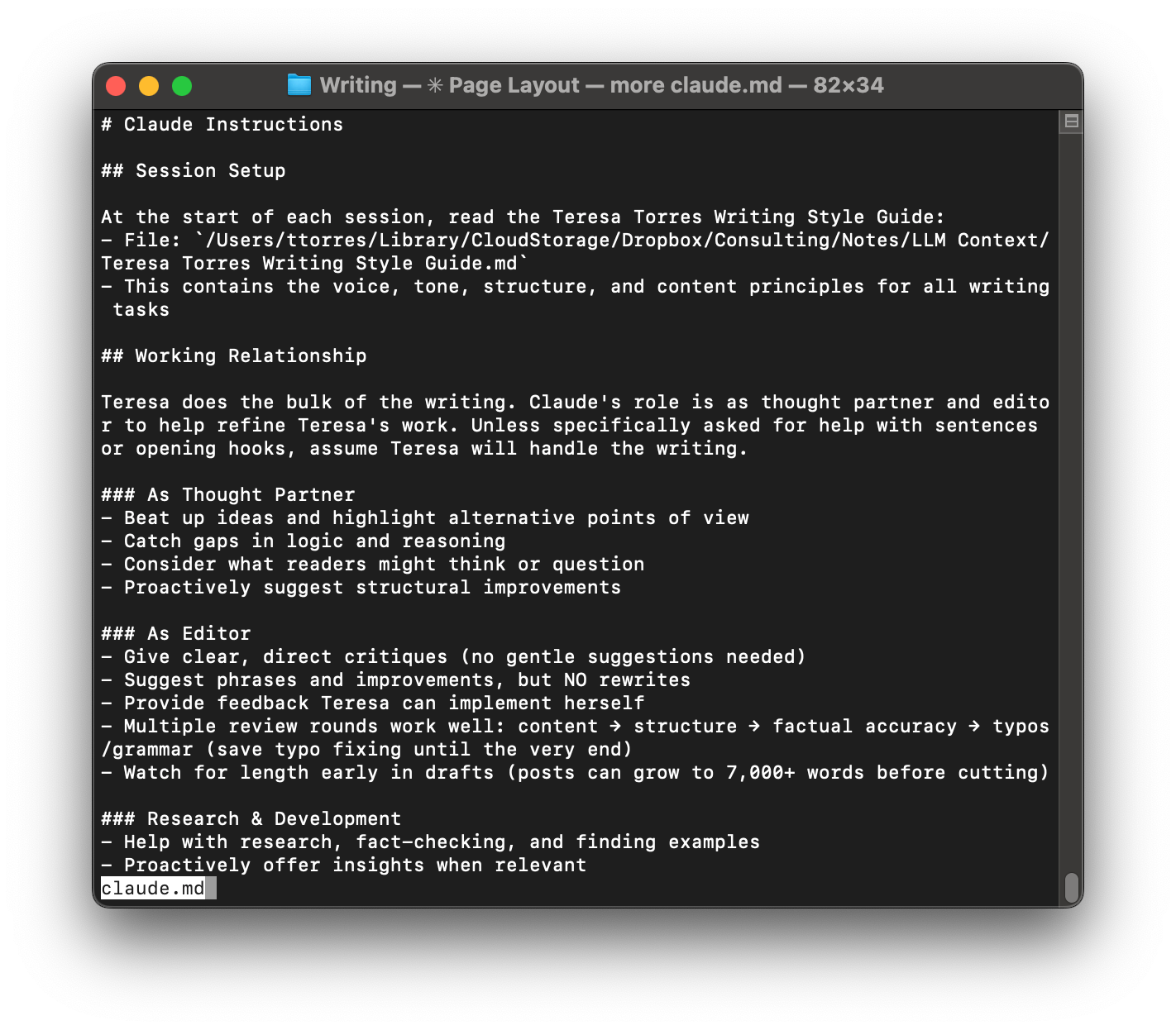
Different Projects have different rules. My task management system works differently from my writing workspace, which works differently from my code projects.
For my writing workspace, my Project CLAUDE.md tells Claude:
- I'm the primary writer; Claude is my thought partner and editor
- Multiple review rounds work well: content → structure → accuracy → typos
- Always prioritize human readability over SEO
- Reference the writing style guide when relevant
For my task management system, the project file covers:
- How my Trello integration works
- File naming conventions for tasks
- How to process research papers into summaries
For my coding projects, the project file specifies:
- Technology stack (Node.js vs. Python)
- Testing framework (Jest for Node.js, pytest for Python)
- Code style and conventions
- Project architecture and directory structure
- Which dependencies and libraries to use
These files live in each project directory as CLAUDE.md. When I'm working in that directory, Claude automatically loads those instructions.
Layer 3: Reference Context (Pull as Needed)—The Real Power
Before we dive into reference context, let's revisit why managing context matters.
LLMs have a context window—a limit to how much information they can process at once. Even when you stay within that limit, research shows that loading too much context degrades performance. There's a phenomenon called "context rot" where the model's output quality deteriorates when the context window gets too full, even if you haven't hit the technical limit.
This means we need to tightly manage what we load into Claude's context. We want small, targeted files—not long, comprehensive ones. Give Claude exactly what it needs for the task at hand, nothing more.
Your CLAUDE.md files get loaded in every relevant session, so keep them concise. You don't want them filling up the context window. Think of them as where you store rules and preferences—how you work, what conventions to follow, what workflows to use.
For more detailed context, create separate context files. You can then reference these as you need them. You can even describe in your CLAUDE.md files what context files exist, and Claude will automatically know to use them.
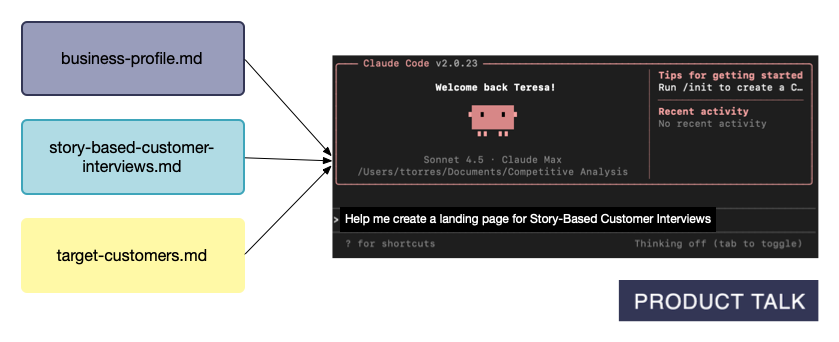
Here's what most people miss: You don't put everything in your global or Project files. Instead, you create separate reference files that Claude only loads when you need them.
Okay, let's get into how I structure my context files. This rest of this article is for paid subscribers. I'll be sharing:
- Exactly which context files I created and why.
- How I got Claude Code to help me create them so that this wasn't a tedious task.
- How I broke them up into small, reusable files so that Claude only gets exactly what it needs for the task at hand.
- How I keep it all up to date.
- Step-by-step instructions for how you can set up a similar memory system.
Let's dive in.