Behind the Scenes: Building the Product Talk Interview Coach

I’ve been diving deep into how generative AI can help us build new skills.
I’m firmly in the “AI should augment (not replace) humans at work” camp. I’m concerned about the short-term impact on entry-level employees. I’m concerned about brain rot in the rest of us who seem so willing to outsource our thinking to AI.
But don’t get me wrong. I’m a big advocate for this new technology. I use it all day long. But I’m deliberately using it as a thought partner, as a teacher, and as a coach.
A few months ago, I started asking, “What does this new technology make just now possible in the context of teaching?” And boy, did I jump down a rabbit hole.
I started by dabbling in a number of areas. I was curious to find out:
- Can AI help us create interview snapshots?
- Can it help us identify opportunities that we missed in a customer interview?
- Is it good enough to do our synthesis for us?
- Can it give us the type of feedback that is required for deliberate practice?
While the jury is still out on many of these questions, that last one really grabbed me. Since April, the students in our Continuous Interviewing course have been getting AI-generated feedback on their practice interviews.
Like all AI products, it started out pretty good (but definitely not great) and has slowly gotten better with time. There’s still more work to do (and I suspect there will be for a long time). But it’s already impacting students’ learning outcomes.
Along the way, I’ve learned a lot about what it takes to build high-quality AI products and have much more to learn. I plan to share the full journey with you. This is the first installment—a webinar I recorded in June 2025 to share my progress up until that point.
You can watch the video or read an edited transcript below. I do refer to a lot of detailed visuals in this webinar. So if you are able to, I recommend watching this one.
(If you received this in your inbox, and the video doesn’t show up, open this post in your browser.)
Full Transcript (edited for clarity and readability)

In March, I had an accident where I broke my ankle and had to have ankle surgery. That meant that I spent three months at home with nothing to do. I had a lot of free time. And so I decided to use that time to answer this question: What does generative AI make just now possible?
This story is literally about the last three months. Everything you're going to hear in this story started in late March. I think I started this project around March 23rd after I came out of my drug-induced haze of recovering from surgery. And you're going to see how quickly I was able to make progress.
The other thing I want to note is: I will highlight the first time I wrote code. One of the themes in this talk is going to be about who does what. Should it be product managers? Should it be engineers? I got pretty darn far without having to write a single line of code. So we're going to get into that as well.
This was my driving question: I literally sat on the couch with my foot up, with my laptop, trying to figure out how I could use generative AI in the context of teaching. This is the really important part.
I'm on LinkedIn like all of you. I see a lot on LinkedIn posts about people using AI to automate some of their discovery. They're interviewing synthetic users or using AI to synthesize their interviews.
I've run these experiments. This technology is too new to say those things will never work. But my interest is in using generative AI to help humans build skills to connect with humans, so I'm not that interested in how to automate all of this away.
I think as long as we're building for humans, we need to be talking with humans, building empathy for other humans, and engaging with humans. So a lot of my focus was: How can I use these tools to facilitate teaching and skill building?
Setting the Stage: Understanding the Context of the Continuous Interviewing Course

And this particular project was focused on our Continuous Interviewing course. There's a couple of things I want to highlight about this course just for context for the tool. I promise this webinar is not a sales pitch. I think a little bit of context will be helpful for understanding the tool that I built.
The Continuous Interviewing course is all about effective customer interviews. There's a couple things that we focus on. We focus on how to ask the right questions. I teach a style of interviews called story-based interviewing, where we focus on collecting stories about what our customers did in the past. We also practice active listening techniques. So this is a lot about how do we ask the right questions and how do we be present.
Across all of our courses, a big part of our teaching philosophy is practice oriented. We do a lot of hands-on practice. And in this interviewing course in particular, students go through the material and then they come to class and they practice interviewing each other.
A lot of my course design is influenced by Anders Ericsson’s work and this idea of deliberate practice. In the idea of deliberate practice, we need feedback on our practice. We do a lot to teach students how to give each other feedback on their practice.
When I started to ask this question of what does generative AI make just now possible, I was wondering, can we help students give each other better feedback on their practice interviews?
And for those of you that are familiar with educational research or teaching nerds, a big idea in teaching is to model what you want students to do. It led to this question of: Can we model what good feedback looks like? And this led to me experimenting what has now become the interview coach.
This is the context. The problem I'm trying to solve is that I have a bunch of students practicing their interviewing skills. I want to give them better feedback. I want to help them give each other feedback. How do I model what good feedback looks like?
And so I literally sat down and I started to play with how I can teach an LLM to give students feedback on their practice interviews. Now in our courses, we already have a rubric. We're already teaching our students how to give each other feedback.
This is one of the rubrics we give them. In week one, when they're practicing, they're focusing on collecting a good customer story. And we break this down into four key skills.
The first skill is: How do I open with a story-based question? I'm asking something like, “Tell me about the last time you watched Netflix” and not something like, “What do you like to watch?”
We teach them to set the scene, to get context for the story. This helps the participant remember their story. It also helps the interviewer better understand their story because they understand the context in which it occurs.
We teach them how to build a timeline. How do you collect the full timeline of what happened?
And then most humans are really bad about staying in the specifics of a story. We tend to generalize. So I might say something like, “We watched an action movie, but I actually really don't like action movies. So that's not what I typically watch.” I just went from a specific to a generalization. The fourth skill we teach in week one is how do you redirect generalizations back to the specific story?
We already had this as part of our course. This is something we give students when they're listening to each other's interviews. They're listening for how they did on each of these skills.
The Interview Coach MVP

In my very first interview coach MVP, I literally started in ChatGPT. I set up a custom GPT. For those of you that are brand-new to some of these tools, a custom GPT lets you set some custom instructions. You can upload some files. And I started very simple.
All that was required for this first MVP was a $20 subscription to ChatGPT and a $20 subscription to Claude. I tried out both. I wrote a really simple prompt.
In fact, if you want to steal this, you can, because it relies entirely on public information. I just told the LLM: “You're an expert in Teresa Torres's method of story-based customer interviews.” I gave it a couple of articles it could read. These are public blog posts. And then I uploaded a version of this story-based rubric where I basically told it a little bit about each of these four dimensions.
And I was just trying to understand how good it would be.
This was literally my MVP and I think I did this on day one. On the very first day playing with some of these ideas, I just was wondering how good is this going to be? And it was pretty surprising.
I actually ran one of my own interview transcripts. My interview wasn't a story-based interview. And I was actually really curious to see if it would catch that. And it did. It's telling me I actually didn't do a good job of asking a story-based question. It's telling me I didn't really set the scene.
It does tell me I built a timeline, but I'm already—in my one-hour prototype—starting to get some pretty interesting feedback. It can understand this idea of a story-based interview. It can understand these dimensions of my rubric.
This was a pretty crude prototype, but it was already better than I thought it would be. It got me thinking: It turns out all the work that I've done to teach humans these skills—developing rubrics, developing lesson plans, teaching clarity of ideas, teaching know-how—is a lot of the same skills we need when teaching an LLM how to do the same thing. It turns out all the work that we do to teach humans is very applicable to teaching an LLM.
I thought, if I can get this far in an hour or two, if I put some time into this, how good can I make this? But I had a concern. I wanted to know how I could make it real. I'm working in the context of a custom GPT and a Claude project. These are on my own private account. How do I make this real?
I did notice that both OpenAI and Claude were able to do this fairly well. I didn't see a huge difference. You're going to see in a little bit, there was a moment where I did see a huge difference, and I'll share what that was and what I chose to use. But at this point, they're both fairly equivalent.
A Pragmatic Pivot Point: How Might I Deploy the Interview Coach?

My one or two-hour prototype impressed me and I started to ask more pragmatic questions, like, “How might I deploy this? How do I get it in the hands of my students?”
And I ran into a couple roadblocks right away. The first one is there's no API access to Claude projects. So I can't share a Claude project with my students. Now I can share a custom GPT with my students, but the problem is custom GPTs are a little bit hard to lock down. They're either public to everybody, which I don't want—I want this just to be a tool for my students. Or they have to be on my team. I certainly don't want to pay $20 a month for everybody in my class just to have access to my tool.
And so I very quickly ran into this issue where the way that I was prototyping wasn't going to turn into a production-quality product. I really got stuck an hour or two in. I was thinking, “Okay, this is a fun toy, but how do I make this a real product?”
The other issue I ran into is that I really need to embed this in my learning management system. This was designed to be a course tool. I needed to be able to embed it in an access-controlled tool.
I wanted to rate limit it because I was really afraid of how much this was going to cost me. Were people going to use this a thousand times, and I'm just paying for all the API calls out of pocket?
And I really wanted to be able to spin up more tools like this. Even after an hour or two of prototyping, I was saying to myself, “Wow, I can see the value of this in teaching. If I look across all my courses, I could build a lot of feedback tools.”
I started to get ideas for simulation tools where you could interview the LLM to practice building your skill. So I decided, okay, I'm sold. There's a lot that's just now possible.
But I got a little bit stuck with: How do I deploy this? How do I make it real? How do I meet some of these requirements?
Turning to Replit: Will It Allow Me to Deploy Teaching Tools Effortlessly?
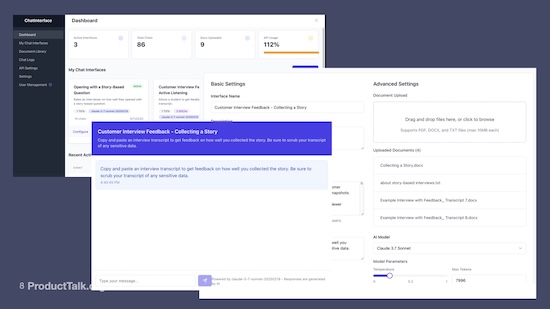
And that's when I learned about Replit. And so I went to Replit and I tried to determine if I could build a tool in Replit that allowed me to deploy teaching tools effortlessly.
I realized that what I really want is Claude projects—because I was having a lot of success with Claude projects—but in a way that I could embed the chat interface into my LMS.
I went to Replit, I used the agent, and I just told it what I wanted. And I got pretty darn far. I was able to spin up this tool that's just a chat interface builder. I was able to build different chat interfaces.
I was able to name my chat interface. I could decide who had access to it. I could define a system prompt that the chat interface used. I could upload files that became part of the prompt. I could provide instructions to my students. And I could also choose a model, set the temperature. I also added rate limiting.
And this allowed me to embed a chat interface. It was just through an embed code right in my LMS. And I could even rate limit based on my student's ID. I can embed this in the LMS. My LMS could pass the student ID to this tool, and I could do rate limiting, I could have custom prompts, I could add all my proprietary course content to it. And that was all safe.
I had never used Replit before. I built this tool in two days. It blew my mind. I really felt like the future is here. This is spectacular. And I was thinking I was going to have a million of these tools—I'm going to build the interview coach, the interview snapshot coach, and the opportunity solution tree coach.
I thought it was amazing that I now have a tool that allows me to deploy teaching tools.
Choosing My First Test Population: Alums of My Continuous Interviewing Course

Next I had to think about who I was going to deploy this to. Who's my first test population? And what I decided to do—because I'm focused on teaching—I decided to deploy it to my alums of my interviewing course.
I didn't want to deploy it to my students first because I didn't know how good it was. And I don't want to interfere with people who are currently building the skill. I wanted to deploy it to people who've already built this skill and see how they do with it. And so I deployed it to my alumni.
I also did this very hands-on. They gave me their transcript. I uploaded it to the tool because I wanted to be able to see the quality of the coaching feedback. I was really concerned whether it was going to be good enough.
Here’s a real example. An alum gave me their transcript and gave me permission to run it. It was one of my very first tests with real content that wasn't one of my own interviews.
By this stage it had grown a little bit. I scored the transcript on four dimensions. These came from my teaching rubric. And then the LLM says, “What did you do well?” And it gives some feedback about what they did well.
In this case, the student did a fairly good job. This was one of our alums. They were already learning how to do story-based interviewing. The LLM told them they did a great job asking a story-based question. They did a good job collecting the timeline. They did a good job clarifying details.
This is all great, but our students don't just need to be told what they did well. We also want to give them room for improvement.
It also gave some areas to practice. There were some missed opportunities for setting the scene. They could have been more consistent with redirecting generalizations. They missed some opportunities to explore some emotions.
And then the LLM also gives an overall tip. It's basically saying overall, this was a really good story-based interview, but there are some opportunities for improvement.
I sent this to the student and I said, “Give me your feedback. Was this helpful?” And the student responded, “Wow, this is shockingly good.”
So now I could see that it's not just me who's amazed by how good this is. I've now run it through a number of our alums' transcripts. I did this for about a dozen alums with real transcripts, trying to understand if this was helpful and how people responded to the feedback.
And I saw there was something real here. So my next question was: What do I do next?
Two Weeks in, I Was Ready to Release It to My Next Cohort… And Quickly Uncovered Some New Issues

I decided to release it to my April cohort. I was two weeks into this project at this stage. I started at the end of March. We were now in early April. I had a cohort of Continuous Interviewing starting in April.
I offered it to all of my April students: If you want to get feedback on your live class practice interviews, here's how it's going to work. You're going to record your session, you're going to send me the video, we're going to run your transcripts through the interview coach, and we're going to see how it does.
Now for anybody who's ever released a product, ever, with real customers, you uncover some new issues. And of course, I uncovered many new issues.
The first one was: Students were hitting their rate limit artificially. By design, I set the rate limit as two practice interviews a week. That's because they do a practice interview in class. I wanted them to be able to run their transcript through the interview coach. And then if they tried it in their own work, I wanted them to be able to run a second interview.
Well, students were actually hitting their rate limit by running their transcript and then asking the LLM for feedback. It would basically say, “You missed an opportunity to build the timeline here.” And the student would type in, “Can you give me the excerpt of where I missed that opportunity?”
What was great was students were engaging with the tool like it was a real coach. The feedback was helpful enough that the students wanted to know more. But the problem is my rate limits were based on messages to the LLM, and they very quickly ran out of messages.
The other thing I noticed is that students really wanted excerpts from their interview, from the transcript. They wanted the tool to show them what they did well or what they could improve. They didn't just want the tool to tell them.
Being able to see real traces of student input, LLM response, student input, was really eye-opening on how people wanted to use this.
The second thing that I ran into—which was a little bit problematic—was I noticed that students were uploading their real customer interviews. And I was not prepared for this. I built this tool to give feedback on their practice interviews in class.
Once I realized I was getting real customer data, I freaked out a little bit. Because I don't have SOC 2 compliance, I was storing these transcripts in Airtable. I was a little bit worried about whether I was set up to store real customer interview transcripts.
And you're going to see this is a theme that's going to be pervasive throughout this project. So I started to get a little bit worried about what I did here. Did I open Pandora's box from a data standpoint?
The next thing I uncovered was the interview coach was actually starting to confuse some of my rubric criteria. In some of the responses to students, it was using the guidelines on building a timeline when giving feedback on setting the scene.
And part of this was because my prompt was getting really, really long—like pages and pages long. And that's because I was using one prompt for the whole interview coach. And so it had to know the context for all four dimensions. As I uncovered errors, I was updating the prompt, and it was just getting really unwieldy.
This is when I started to look into how people deal with long prompts. And here's what I ended up learning: A lot of people are using what's called an AI workflow, where they're dividing their big long prompts into smaller tasks, and they're stringing together multiple LLM calls. So I wanted to do that. I wanted to split each dimension into its own AI call.
Next, I Tried to Modify My Tool in Replit—And Failed Miserably

So I went back to my Replit tool and I tried to modify this tool so that each chat interface could actually be a series of prompts instead of one prompt.
I spent a full week going back and forth on this tool and I will tell you, I failed. I could not get Replit to reliably extend my tool. Now part of this is because it got really confused about its own development context. I've seen a lot of people on LinkedIn share similar experiences—you can get your first version of the product out, but then as soon as you try to iterate, it gets confused.
In my case, it got confused about whether we were using Drizzle or Prisma as database schema technologies. It got confused about what React components it was using. And I pretty much lost a week of my life arguing with the Replit agent.
At this point, I got frustrated. I posted on LinkedIn. I asked for some tips. I got amazing tips about using the assistant versus the agent. It helped a little bit.
But at this point, I realized that I didn't actually need a chat interface. And the chat interface was causing a lot of the problems.
One of the first pieces of student feedback I uncovered was that by it being a chat interface, students wanted to chat with the LLM about their feedback, but I didn't build it for that purpose. This wasn't intended to be a multi-turn conversation. It was intended to be: Upload your transcript, get the same type of feedback you might get from an instructor.
Abandoning Replit and Moving to a Combination of LMS Tools and Zapier
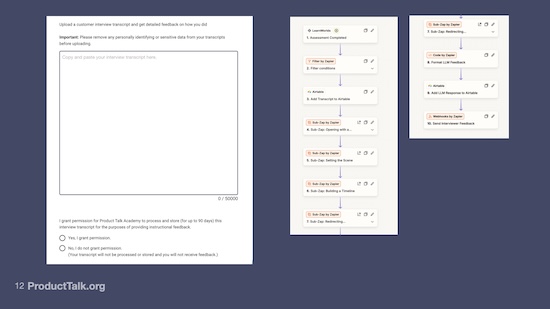
At this point I abandoned Replit. I decided I outgrew this prototype. It was time for a different solution. And this is when I moved to a combination of the tools that my LMS provides plus Zapier.
I moved to a structure where now I'm using a homework assignment in my LMS where they can cut and paste their transcript and submit it and that triggers a zap.
The first thing I had to do was to tell my students, “Before you upload a transcript, remove any sensitive data.” I was a lot more upfront about the fact that I was not set up to reliably store real interview transcripts.
I also added a consent question, saying, “By uploading a transcript, you're giving me permission to store it.”
This is really critical if you're building LLM apps. You're going to see later, to get a good LLM app, you need lots of traces. A trace is the user's input and the LLM's response.
When we get into the quality of how do I know if this tool is good or not, having that data was critical.
And so in the second iteration, I boosted my data practices. I let people know even before they see the upload screen that I'm not SOC 2 compliant. I explained that they need to remove any sensitive information from their transcript. I give them tips on how to do that. And then they have to give me permission to store the trace for 90 days.
Once they submit this assignment, it triggers a zap. This is triggered by a LearnWorlds assessment. LearnWorlds is my course platform.
The next thing that I'm doing is I'm filtering. This is checking this consent question. If they don't consent, the zap just ends, they don't get feedback. If they do consent, I store the transcript. I'm actually just using Airtable.
Part of the reason why I'm openly sharing all the tools I’m using is that I see a lot of people get distracted by all these off-the-shelf tools. I built all of this using tools I already owned.
I store the transcript in Airtable. And then the next four calls are just LLM calls. I'm using the Anthropic API. Each one of these sub-zaps is storing my prompt for each of the four dimensions. They all get returned to this zap so that I can then format the response. So each of these individual calls returns some JSON.
Maybe if you don't code at all, JSON feels like code. It's just an output format that's easy to work with programmatically. It's very human readable as well.
I then format the responses across the four independent calls and I store the response in Airtable. This is really important because I'm trying to get those traces, user input plus LLM response.
And then I email the student the response. And here's the really key part. I also email myself the response. And I still do this because I'm really concerned about quality. I'm really concerned about whether I’m giving my students something that is telling them the wrong thing.
And there have been a couple of times where I saw the response and I saw some errors in the coach and I followed up with the student and I said, "Hey, this was really good feedback. I actually see a concern with this one piece. Let me just correct it for you."
And that was my earliest way of monitoring quality, even though now there's no human in the loop. Students upload their transcripts on their own. The zap runs the LLM calls and then emails the students.
The email that I send to students explains that this is AI-generated feedback. We're not making it look like this is coming from an instructor. We're very honest that this is coming from our interview coach.

We've changed the format a little bit. I've switched because we saw that students wanted excerpts. Now each dimension, the LLM is pulling out excerpts from the transcript and then giving a tip on that excerpt. It's telling them if they did a good job or if they missed the opportunity.
And at this point, every dimension is its own LLM prompt. And by doing that, I saw a dramatic improvement. I can now do excerpts. The coach is giving feedback on each excerpt. We're not just telling students what they did. We're showing them what they did.
In one example, the interviewer is asking, “Could you walk us through your recent substation project you've been working on? And if you talk more about the type of structure, the work you've been doing.” And the tip from the interview coach is that they asked a general question.
They didn't say, “Tell me about your last substation project.” The question went on for a little too long. They asked for too much. This is actually a pretty darn good tip.
In this same example, under setting the scene, we have the same thing. We've got a quote that's from the transcript. And the coach is saying this is a missed opportunity. They just started to tell their story. They should have asked a setting the scene question. Another great tip.
At first glance, this looked amazing. I was like, wow, splitting the prompts is amazing. But then I noticed something. It’s using the same excerpt multiple times. And in one case, it’s saying this is a general question. You should have asked a story-based question. And in another case, it’s saying this is a good story-based question. What's happening?
One of the consequences of splitting my prompts into four different prompts is that now my setting the scene coach doesn't know what a good story-based question is anymore and it thinks this is a good story-based question. And now I'm getting inconsistent feedback across my dimensions.
So on the one hand, splitting my prompts dramatically improved how the LLM did on each dimension, but it meant that sometimes it gave feedback on things that it shouldn't have because another dimension was covering it.
This introduced a whole new set of problems. And I started to get a little bit frustrated at this point. I'll be honest. I felt like I was taking one step forward, two steps back. Maybe if I was being optimistic, two steps forward, one step back.
My Next Question: How Do I Know if My Interview Coach Is Any Good? The Answer: Evals (But It’s Not That Simple)

It started to raise some serious questions for me. I started to ask, “How do I know if my interview coach is any good?” And this is really important to me because for any of you who have taught before, if students already get confused when you give them top-notch, really good teaching materials, if you give them something that's slightly off, it can completely derail them. For me, quality was the most important thing.
At this point, I was just iterating by prompting and looking at traces, prompting, and looking at traces. And what I started to really wonder was: How do I know if my model changes, my prompt changes, my temperature changes, how do I know if they're having any impact? How do I know if I am making this better? I'm just looking at individual traces. This seemed crazy.
And so I started to dig in and I started to research what are people doing to evaluate their LLM-based prompts? And it turns out the answer is evals. Here's the problem: Everybody defines evals differently. It's not the same.

I'm going to talk through three different definitions of evals and why they all frustrated me. We're going to start with the first one. This comes from OpenAI, the company that built ChatGPT. They define an eval as: You describe the task to be done, you run your eval with test inputs, you analyze the results, you change your prompt.
This sounds a lot like what I've been doing. I described the task I wanted it to do, I ran the results, I looked at my trace, I changed my prompt. Is this all evals are? I don't feel confident that what I'm doing is working. For every change, I see some problems fixed and other problems created. How do I know that I'm making a good product? And so I was pretty frustrated by OpenAI's definition.
Then I came across this Python tool, Pydantic Evals, and I looked at their definition. And in this definition, they talk about it as cases and data sets. It's a little bit more sophisticated. It's this idea that you create a data set of examples by providing a bunch of transcripts, a bunch of LLM responses, and the desired output.
And then you run your evals, which literally just means: Send those inputs to the LLM, see what the output is, and see if it's what your expected output was.
And I thought this was a little better, but how do I construct this data set? How do I know that it represents what I'm doing in production? How do I know that it's covering all the possible things that could go wrong?
I was still a little bit uncomfortable with what evals are and how we define what good looks like. And then Lenny came out with his deep dive on evals and we're getting to another definition of evals. In this article, they talk about multiple types of evals, including human in the loop evals.
I thought: That's what I've been doing. I'm looking at lots of traces. I'm looking at the output. I'm changing my prompt. I'm kind of getting there, but it doesn't feel scalable. I'm not really confident my interview coach is good.
A Key Turning Point: Discovering the Maven Course on AI Evals
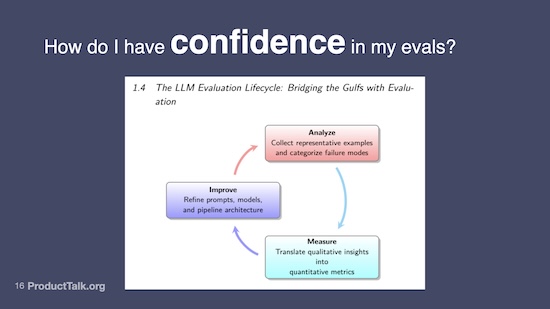
Then I started looking at code-based evals and LLM-based evals. And I started to dig deeper. And thankfully, I came across an AI Evals course (very fortuitously—I discovered it the day before enrollment closed!) that actually really resonated with me and I learned a lot.
Here's what I was really focused on: How do I have confidence in my evals? If I'm creating a data set that's my test set to determine if my LLM app is good, how do I know that data set represents what my students are really going to experience?
The course that I took is on Maven. It’s called AI Evals for Engineers and PMs and it’s taught by Hamel Husain and Shreya Shankar. In the course, they introduced this process: You start by analyzing your traces and doing error analysis. You identify your most common error categories. You build evals for those error categories.
We're talking about code-based evals and LLM-based evals. We're not talking about just running data sets and comparing outputs. And then you improve your prompt. And when you run your evals, you can see whether it got better.
Here's why this really resonated with me: I'm a discovery coach. What is discovery about? It's about fast feedback loops. Suddenly, this was a way to build in a fast feedback loop on my LLM app.
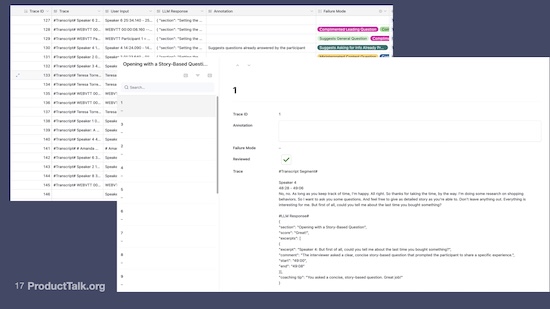
I implemented this process. I had a whole bunch of traces because my students had opted in to let me store their transcripts with their LLM responses. I went through and did error analysis. This is the step that most people skip. What does this mean? I annotated all of my traces. So I went through and I looked at the LLM response.
I did this for each of my dimensions, not each transcript. So far I’ve talked through four dimensions, but I'm actually measuring on seven dimensions. I started annotating what the LLM got wrong.
And boy was this scary because I uncovered a lot of errors. I uncovered things like the LLM was suggesting leading questions. The LLM was suggesting general questions. These are things we teach you not to do. I absolutely do not want a coach who is giving my students incorrect feedback.
At this point, I have not written a line of code. I have a product that's being used by real students. I was able to deploy it. I'm able to evaluate how well it's doing. I've been able to do my error analysis.
I'm storing my traces in Airtable. This annotation tool is an Airtable interface. People get super caught up on what eval tool they should use. I was able to do all of this in Airtable.
So this scared me because I was thinking, this is not good enough. The eye test, just vibe checking my LLM responses, my interview coach looked great. I was getting great feedback from students. But as soon as I started actually doing error analysis, I got a little bit terrified. I was thinking, "Wow, I cannot put this in front of students."
At this point, I got serious about evals.
The Next Step: I Started Writing My Own Evals
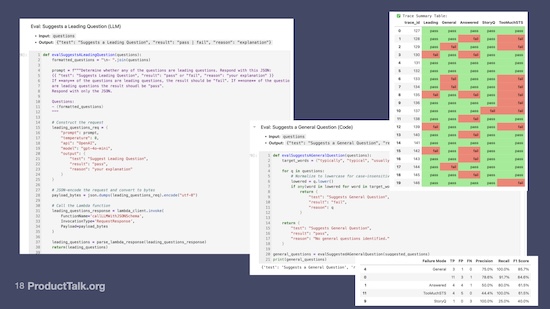
I'm going to tell you a story about tooling. I have written code before. I started my career as a web developer. I know JavaScript pretty darn well. I've been writing in Node.js for the last three years, implementing a lot of the business logic in my business. I had never used a Jupyter Notebook, and I had never written a line of Python. This is a true story.
On a Sunday about three weeks ago, I sat down and started to define my first code-based and LLM-based evals. I did all of this in three days in a Jupyter Notebook in Python.
Why did I use those tools? This whole error analysis process, this LLM-based code-based eval process, is coming from the data science world of machine learning. That's where a lot of these techniques are coming from. They all use Python. They all use Jupyter Notebooks.
I didn't want to deal with an off-the-shelf eval tool. I wanted to learn this process myself. I wanted to make sure I knew it inside and out before I was influenced by a tool’s point of view on evals.
Here's what I did: I wrote my own evals. This is from a Jupyter Notebook. One of my most common error categories was that the LLM was suggesting a leading question, so I wrote an LLM as judge eval.
Here's how this works. An LLM is a judge. All I needed to give it was the LLM response. My prompt is going to 4o-mini. There’s a code block that is calling a Lambda function.
All my production code runs in AWS. But right now, when I'm doing this, at this stage, I'm on my M4 Mac Mini. I'm running in a local Python environment. Remember, I had never written Python. I'm working in a Jupyter notebook.
How did I learn how to do this? I asked ChatGPT: “How do I get started with Jupyter Notebooks?” It walked me literally through everything I was doing. I set up my first Jupyter Notebook. I started writing my first evals.
This is a real eval. This is the full definition of one of my evals. It's just an LLM prompt. It's sending the LLM response plus the prompt to 4o-mini. And it's asking, “Are there any leading questions in this response? Pass/fail.” If there's a leading question, it fails. If there's not a leading question, it passes.
Another one of my examples was the LLM was suggesting a general question, like “What do you typically do?” “What do you usually do?” or “What do you generally do?” This is a really simple code-based prompt. This code-based prompt is just looking for specific red flag words in the questions. These are two examples of my real evals.
How did I get here without knowing Python? I can read code. And Python, it turns out, is a very human readable language. I basically just talked to ChatGPT. I said, I'm working in a Jupyter Notebook. Here's my error category. Here's how I think I would solve this. I think I need an LLM judge. I think I can solve it in code.
And I said, “Help me write the Python.” It wrote the Python. Because it's human readable, I looked at it and said, that looks like it makes sense. If there was something I didn't understand, I said, “Explain to me what that line means.” I cut and pasted it into my Jupyter notebook. I ran it. I tested the data. If it worked, great.
Now remember: I have seven dimensions to the interview coach. This is just one dimension. I actually have about a dozen evals for this one dimension. A lot of them are code evals. Some of them are LLM as judge evals.
Let me tell you the value of this. I can now take a set of traces—interviews plus LLM responses—and run them across all my evals. By the way, I do this right in my Jupyter notebook, and this is what it spits out.
There are columns that show my common failure modes, and it's telling me for each transcript, did it pass or did it fail? In one case, where there is too much STS, it turns out this uncovered a problem in my human grading rubric.
In this particular example, the code eval was actually better at evaluating this than my human graders. And it told me I needed to update my rubric for my human graders. It looks like there were a lot of errors, but in practice, most of the reds turned green.
The story queue eval is actually passing almost all the time. That's a really strong eval.
There’s another LLM as judge. How do I know this LLM is doing the right thing? One of the things I learned in my class is that we can score our judges. So for each of these judges, I can compare their output to human grader output, understand their true positives, their false positives, their false negatives, and understand my error rate on my judges.
I know I just got really technical. This is also the first time I wrote code during this project. So if you’re not an engineer, if I lost you, please do not panic.
Remember: I had never used a Jupyter Notebook. I had never written Python before. I did this in three days.
I’m sharing my first run. There’s a grid that shows how many times I saw errors across these error categories. And there’s a table that tells me if my code and LLM evals match my human evals. Do my human graders match my code graders? Can I trust them?

What does this do for me? It helps me answer: How do I know my interview coach is any good? How do I know that when I make changes, they're having any impact? And what I get from this little table is now I can run experiments.

Every time I make a model change, every time I make a prompt change, every time I make a temperature change, or a chunking strategy change, or any other change, I now have a fast feedback loop. I make the change, I run my evals, I decide to release it or toss it.
How am I making that decision? Does the grid get more green? And if it doesn't get more green, where's my problem? What error category is failing more often? And because I'm not just relying on a fixed data set, I can run these evals forever. I have low-volume traces because I'm just using this in a course. I can run this on every single trace I collect and always have an understanding of how my coach is performing.
The slide I’m sharing was actually my very first eval run. I have made a million changes since then. I have run probably hundreds of experiments. A lot of these reds are turning to green. I can have a lot of confidence because I now have a fast feedback loop.
When it comes to human graders, so far, I have been my only human grader. I am going to move to a point where my instructors become my human graders as well, and I'll show you what that looks like.
I literally created an Airtable interface, which I’m showing in this next slide. All my traces are on the left. I annotated in this box right here. I literally typed in what's wrong with this response, and then I marked it as reviewed. And then after I created everything, I came up with my most common failure categories. And that's what I built evals around.
My human grading process was: I looked at traces in Airtable. I annotated them. I used those to generate failure categories.
What’s Next for the Interview Coach?

So what's coming next? There's a lot left on the interview coach. I am still iterating. I am still uncovering new failure categories. I'm still writing evals. I'm still making improvements based on what I'm learning.
I’ll be partnering with Vistaly to offer the Interview Coach on real customer transcripts.
One of the things that I uncovered was this data problem. I am not set up to store real customer interviews, so I'm actually partnering with Vistaly.
If you're not familiar with Vistaly, they are a product discovery tool. They give you a tool for building your opportunity solution trees. They allow you to upload transcripts. They help you identify opportunities from transcripts. They are SOC 2 compliant. They are set up to store real customer data quickly.
And I am going to be partnering with them where our course students will be able to run the interview coach on their real customer transcripts. We are hoping to launch a beta group soon.
Everybody in our course gets access to the interview coach on their practice transcripts. Through Vistaly, we're able to give feedback on real interview transcripts too.
As part of this partnership, I had to get away from prototyping and get closer to a real production environment, so I moved out of zaps.
I moved off of Zaps and am now orchestrating LLM calls with Step Functions.
I'm now working out of AWS Lambda and Step Functions. I'm doing that for a couple of reasons: It's a much more reliable production environment. I can run a mix of Node.js—which is what most of my code base is in—and Python. So I run all my evals in Python, I run most of my code in Node.js. A Step Function lets me orchestrate both. So when a student uploads a transcript either to Vistaly or through the course interface, my interview coach code runs. We send the email to the student. My evals run immediately afterwards.
I’ll continue to experiment and offer other AI-based teaching tools.
What else is next? This is the first of many LLM tools I've been experimenting with. I'm also working on an interview snapshot coach. I'm also working on creating interactive interview simulations where you can practice your interviewing skills and get scored on how you did through a simulation.
From my standpoint, I'm very excited about the potential of these tools for teaching and skill building. We're going to be rolling out these tools across all of our courses.
One thing this did for me is it really opened my eyes to how the world is changing with LLM apps and evals. And it started to raise a lot of questions. Why aren't more teams doing evals this way? Why are we just relying on data sets? Why aren't we doing proper error analysis? Why aren't we doing code-based and LLM-based judges?
It also really raised the question of who does what. I did have to write some code to implement this, but I do think product managers need to be involved in evals from beginning to end because they might have the most domain expertise.
I'm also really curious about what role the customer might play in evals, and I'll be running a lot of experiments on how to get customer feedback on traces and how to have customers help with error analysis.
And then I'm curious to hear from you. What do you want to know more about? Because I'm definitely going to be doing more in this space.
Q&A
What are the final tools used and what was built with code?
To get started, I used Claude Projects and OpenAI custom GPTs. I then moved to a Replit app that I very quickly outgrew. I then moved to an assessment tool, like a homework tool in my LMS that triggered a zap. And then eventually I moved to AWS Step Functions, which by the way is still triggered by a zap because in my course, the trigger action is submitting the assessment that triggers a zap that triggers my Step Function. In Vistaly, uploading a transcript is the trigger, but they call my same Step Function in my AWS environment.
For evals, I used Airtable to store my traces and Airtable interfaces as my annotation tool. And I write my evals and execute my evals in a Jupyter Notebook. When I run my daily experiments, I'm working out of a Jupyter Notebook. When I'm ready to release to production, my code blocks get pushed to AWS Python Lambda functions.
How did you improve the response that you corrected for the students after checking them?
This is really an iterative process. There's a lot of ways to make improvements. You can try different models. You can change your prompts. You could try changing temperature settings. You can divide a single prompt into lots of mini prompts. There's a million things you can change. And this is where evals are really important because you have to experiment with a lot of things. When I started, I didn't even know what temperature was. I just had to learn this stuff.
There's a million courses out there. There's also a lot of free resources. I relied heavily on the Anthropic Prompt Guide. I've been reading a dozen blogs where people are just sharing, kind of like this story. Here's what they did. Here's what they tried. Here's what worked. Here's what didn't work.
I did take a paid course. I took the AI Evals course on Maven, which I recommend. That course is for engineers. A lot of the people in the class are ML engineers, so if you're not code savvy, it might be a little bit hard.
I would love to hear from you if there is a part of the story that I shared that you would want to know more about—whether it's evals, error analysis, or tooling.
I'm particularly really interested in evals because it seems the closest to the discovery feedback loop, so I probably will be doing more there. But definitely tell me what you'd love to know more about because I will be doing more events and probably even a course on this stuff eventually.
When do you think it's safe to release such an AI coach product?
I'm constantly in my head about whether this is good enough. Does it need to be perfect? It's probably never going to be perfect. We're talking about non-deterministic products and non-deterministic output. My concern is identifying the failures that will derail a student.
For me, a lot of those are those general questions, those leading questions. I don't want my coach suggesting a bad behavior. And so I've prioritized my error categories based on the ones that I think are the most catastrophic from a learning standpoint. Those are the ones that I prioritize as I iterate on my prompts and as I iterate on my evals.
These tools are never going to be perfect, but it's just like anything. We have to evaluate when good enough is good enough.
Your original Python evals were based on finding keywords in the transcript. Did you ever expect that testing method to account for words?
One of my evals is based on words in the LLM response. I'm not looking for if the interviewer asked leading questions, I'm looking for if the coach suggested a leading question in their coaching tip.
And I found in my experimenting, at first I started with the LLM as judge for that eval. And actually, it was hard to explain a general question, I struggled a little bit with that. And after looking at like over 100 traces, I realized that almost every general question had one of those keywords.
Now, is that a rock solid eval? No, it might end up being brittle in practice. I can always experiment with also having an LLM as judge. And because I can score my judges against human output, I can evaluate which judge is going to perform best over time. And I'm still doing a lot of that work. That's a lot of my iterative work.
What tools did you use to generate the transcripts?
My students are submitting the transcripts, so my user input is a student's real interview transcript.
What would it take for you to feel comfortable releasing this as a product at scale?
This is a great question. One of the biggest challenges I have for me personally releasing this product at scale is I do not want to go through the data process to do this on real customer data. I don't want to be SOC 2 compliant. I'm a company of one. It costs tens of thousands of dollars. There's a ton of ongoing data practices.
This is why I've partnered with Vistaly. They've already done that. They do that work. So I will be offering the interview coach as a product at scale on real interview transcripts, but I'll be doing it through a partnership with Vistaly.
I suspect what's behind that question is: How do I know it's good enough for that? Through our partnership, we are doing a very controlled iterative release. We're starting with a very small number of beta customers that are opting in to letting us see full traces so we can continue to run evals, we can continue to get an error rate, we can continue to see which failure modes are coming up, only when we're confident that it's good enough feedback that we'll then release it to more customers.
We're also requiring that those customers have access to our curriculum content. So they either have to be a student or an alum of our Continuous Interviewing course. That is because our rubric is very based on what we teach.
For example, a lot of people ask, “What is setting the scene?” The setting the scene feedback doesn't make a lot of sense unless you've gone through our course content. A lot of our July beta customers are going through our July cohort.
When we do a big launch in September, as part of that launch—I'll give you a sneak peek—we're also going to make some of our interviewing teaching content accessible to more people.
Have you found any limitations on the evals already?
The biggest thing that's hard about evals is when you do code-based evals and LLM as judge evals, your evals are almost a product in and of itself. So there's a lot of iteration on getting your eval scores to match your human grade scores. But when you put that work in and you get high scoring judges, it allows you to have a lot more confidence in the quality of your LLM product.
So for me, that work is well worth it, but it does take a lot of iteration.
For any LLM eval example, did the LLM define leading questions or did you provide a definition?
I provided a definition of leading questions and that's part of that iteration on that eval. I had to iterate with evals. I want to use the smallest model that is going to be good enough because I want to keep costs down, but I also want to make sure my eval is reliable.
On the slide where I showed my judge scores with true positives, true negatives, false negatives, false positives, those are my judge scores. That's helping me understand whether my judges match my human graders.
In this case, I'm the human grader, and it's helped me understand the quality of the judges, and the judges are helping me understand the quality of the coach.
What did you mean by using evals instead of data sets?
Data sets are like: I have a huge spreadsheet of inputs and the desired output and I run the input through the LLM and I look at whether the output matches my desired output. That works really great when your LLM app is assisting you with things like “help me find a movie recommendation” or “tell me who's in this movie,” where you can define inputs and desired outputs.
With interview transcripts, there's a lot of potential good enough outputs and so if you’re just defining a data set of good and bad traces, it's really hard to have confidence that that covers everything.
Whereas if I do my error analysis on my traces and come up with error categories, and I'm writing my code-based evals and my LLM-based evals, my LLM as judge evals based on those error sets, those error failure modes, then I can have a lot more confidence that it's matching what I see in production.
What was your process to keep track of the result of your changes in the prompts?
That's evals. For every change that I make, I now run all my evals and I'm getting tables so I can evaluate if this change improved things and if I should release it. Or if this change made things worse and I should toss it.
I keep a release log. So in Airtable, I have a table of product releases. I'm keeping track of every change that I make. I'm keeping track of the experiment results for that change, and I'm making a decision about whether it gets released to production or it gets rolled back because it didn't improve the overall quality.
How do you version your configuration and results of evals like the prompt and other config?
One of the things I'm doing that's really simple is whenever I run my Jupyter Notebook, I make a change, I run all my evals, I get output, I actually save that version of my notebook with all of the output and I commit it to GitHub. So all my experiment results are version controlled through Git.
On that Sunday when I started writing my evals, I had never used Git before. So if you're not an engineer and you've never used some of these tools, I literally went to ChatGPT and I said, “I'm starting to work out of a Jupyter notebook. I've never used Git. What do I need to do to version control my notebooks?”
I did that for my code and then I said, "Okay, I want a version control on my output, so I have a record of my experiments. How should I set it up? Just walk me through it.” And ChatGPT walked me through all of it.
I’m confused by the use of the Jupyter Notebook. What did it do for you that Zapier didn't?
Jupyter Notebooks, if you're not familiar with coding notebooks, it's a mix of markdown plus code blocks that you can actually execute. So I'm not just writing my code in the notebook, I'm actually running my code in the notebook. There’s a block that’s the output of me running all my evals that shows up in my notebook.
And then I can commit that notebook to Git with all that output data so that I have a history of every experiment that I've run with the results. And then that allows me to compare prompt A vs. prompt B, so it's like an A/B test.
I am starting to believe that maybe Jupyter Notebooks are how product managers and engineers can work together on this. Because I do think the product manager is going to be making all these changes, experimenting with models, experimenting with prompts, but the engineer is probably writing those code blocks.
I can now run 20 experiments in a day, because I can make a prompt change, run my evals, make a temperature change, run my evals, make a chunking strategy change, run my evals. I can do that all day long. I don't want to have to go to an engineer and say, “Can you run the evals?” I can do it right out of my notebook.
So it's like I have my own development environment that's not touching production. I can't break anything, but it allows me to execute all my evals and get scores so that I can run all my own experimenting locally and it's only when I find something that is a good enough improvement that I can push it to production.
How are your students generating transcripts?
They are conducting interviews and recording their interviews. Right now they have the option to send me the video and I create the transcript using MacWhisper or if they already have a tool that's giving them transcripts, they can just send me the transcript.
When you talk about how many days something took, was this pretty much the only thing you were doing and do you mean an eight-hour workday or some other kind of day?
Really great question. I do run my own business. I'm a company of one. We have classes running all the time. There's a ton of administrative work. I don't think I ever had the luxury of one full day where this is all that I did. I also, as a human, do not have the capacity to work probably more than eight hours a day. I get a lot of mental fatigue, especially doing this kind of work.
Full transparency: I started this project in late March. I've probably been working on it 60% of my time during that period and was able to get this far. Now, remember, I do have some coding background. I'm not totally a beginner, but for a lot of the coding skills required for this, I had ChatGPT walk me through it.
What's the rough cost to process a single interview?
This depends entirely on the token length. In our courses, we do short interviews. We're doing eight-minute interviews, so we get lots of rounds of practice in. Those transcripts are very inexpensive to process. They're costing me between 2 cents and 20 cents. And it depends on how many evals. So I do eval cascades. I don't run all my evals on every transcript. I have a set of helpers that look for early signs of things. And then if those fail, it triggers more evals. So I'm trying to trigger cascade my stuff to keep costs down.
For real transcripts, if we're looking at like a 30 to 40 minute interview, those can be 30,000 tokens plus. I have to chunk those. I have to chunk those for the interview coach. I have to chunk them for the evals. This is actually the experiment I'm running right now. I'm getting a lot smarter about which evals need the full transcript, which evals can use just part of the transcript, which small models are good enough.
That's a lot of the work I'm doing right now to support the Vistaly integration. As transcripts get longer, this whole interview coach problem gets a lot harder because while LLMs have really big context windows, their performance across a big context window starts to degrade as the context window gets bigger. I've had to learn a lot about chunking strategies and how to optimize the right chunking strategy for the right eval.
Am I endorsing Vistaly?
I am. I'm officially an advisor for Vistaly. I'm a big fan of their team. They really get my work and they're building a pretty darn good tool to support discovery. So if you are looking for a tool to support opportunity solution trees, processing interviews, KPI trees, they're fantastic. Definitely check them out.
Some Closing Thoughts: I’m Continuing to Explore the Role of Evals in Discovery
To close out, I’d like to say that evals fit that fast feedback loop that is really similar to the other stuff we do in discovery, so I'm really trying to learn how to do this well, and I want to help other people figure out how to do this well.
Stay tuned. I'll definitely be doing more events and writing more about this topic.
Comments ()