 Have you heard? My new book Continuous Discovery Habits is now available. Get the product trio's guide to a structured and sustainable approach to continuous discovery.
Have you heard? My new book Continuous Discovery Habits is now available. Get the product trio's guide to a structured and sustainable approach to continuous discovery. Now that you are measuring open, click, and conversion rates for your emails, it’s time to look at how to improve them. Let’s talk about A/B testing, sometimes called split testing.
Far too many people hear A/B testing and think button colors and small wording changes. It is true. You can A/B test these types of changes. But it’s not where you should start.
Do you remember fifth grade science class? Okay, neither do I. But you probably remember something called the scientific method. Maybe you even participated in a science fair. Don’t worry I won’t tell anyone. You probably followed a process that looked something like this.
- Start with an insight or question.
- Formulate a testable hypothesis.
- Design an experiment to test that hypothesis.
- Run the experiment and measure results.
- Evaluate results
- Draw conclusions.
This is the exact same process you want to follow when you run an A/B test.
Start With An Insight
Don’t start by making a list of each and every change you could make and test every variation. This method will take you years to stumble on anything of value and is akin to throwing spaghetti at the wall. You aren’t a room full of monkeys trying to recreate Hamlet.
You are a smart product manager who can start with an insight. Use your critical thinking skills. Start from the perspective of the email recipient. Why wouldn’t you open this email? Why wouldn’t you click on the content in it? Generate all the reasons. It might look something like this:
Why aren’t you opening my email:
- You get too many emails
- You’ll do it later (and of course never do)
- It looks like spam
- You have no idea who I am
- You don’t think its important
Why aren’t you clicking on the content in my email:
- It’s not relevant to you
- It looks like spam
- It will take too much time
- You’ll do it later
Now ask yourself, how might you overcome some of these problems.
- How can you create a sense of urgency?
- How can you make your email less spammy?
- How can you show credibility?
- How can you improve the relevancy of the content?
This approach helps you look for strategic changes rather than tactical ones. Want to learn more? KissMetrics has a great article about strategic optimization vs. tactics.
Next, generate a bunch of ideas. Take the best ones and write some hypotheses.
Formulate a Testable Hypothesis
A testable hypothesis is a statement that can be refuted by an experiment.
This is such an important part of A/B testing that is so often overlooked that I’m going to say it again. A testable hypothesis is a statement that can be refuted by an experiment.
Lets look at a couple of examples . You might think that including your brand name in the from line will increase your credibility. So you might write:
- Including the brand in the from line will increase my credibility.
How are you going to test this? How do you measure credibility? If you found a way to measure credibility and credibility increased but people still didn’t open your emails, would you care? Probably not. Try this instead:
- Including my brand in the from name will increase open rates.
This can be measured. You can design an experiment to test this. This is a good hypothesis.
How about this one?
- Including an expiration date in the subject line will create a sense of urgency.
This may be true. Or it may not. How do you measure urgency? How about this instead:
- Including an expiration date in the subject line will increase open rates.
Again, this can be tested. It can be refuted. Or it can be confirmed.
Design an Experiment To Test That Hypothesis
Let’s look at how we might design an experiment to test this last hypothesis.
Many people will just want to change the subject line of their emails and see if their open, click, and conversion rates go up. But that’s not an experiment.
An experiment tests one thing at a time. It has variables and a control. The variable is the thing that you are changing, in this case, the subject line. The control is the old version of your email.
Let’s suppose you send a weekly digest to your subscribers. You might argue that you can compare this week to last week. This week is your variable and last week is your control. But that isn’t a good experiment.
What if last week, 20% of your users lost email access for a day due to an ISP outage? What if this week some of your users read an article about taking action on email as soon as they read it and are highly motivated to apply what they learned? What if last week your email was delivered on Tuesday and this week your email was deliver on Thursday? There are any number of variables that could interfere with your comparison of last week to this week.
Instead, for any given time period, you want to split your audience into two groups. Your variable group and your control group. You want everything to be the same for these two groups, except for the variation you are testing.
To keep it simple, let’s suppose that for this week’s email, half of your audience is going to get an email with an expiration date in the subject line and the other half is going to get the same subject line you have always used. This is a good experiment. If this is the only change between the two emails then you can attribute any difference in how they perform to the change that you made.
Now you have to be careful to only make one change at a time. Suppose you also want to improve the relevancy of the content in your email with the goal of increasing click through rate. You might think well my first experiment is impacting open rates so you go ahead and make both changes.
This is a problem. Subject line changes can impact click through rate. Suppose the click through rate does go up. You’ll have no idea why. Was it because of the subject line change? Or was it because of the content change?
To avoid this, make sure for each variable and control group you are only testing one change at a time.
Now you can run multiple experiments at once by segmenting your audience. For example, if you have 100,000 subscribers, you can run one experiment on 10,000 of them and a second experiment on the next 10,000. Just be sure that when you segment your audience that your segments are large enough that you are likely to get statistically significant results. More on that in a minute. Also, do make sure each variable has a valid control group for comparison.
Run The Experiment And Measure Results
Once you’re identified your hypothesis, defined your segment, and created a variable group that you can compare to your control group, it’s time to run your experiment.
Before you start, determine for how long you are going to run your experiment and ignore your results until that period ends. Evan Miller explains why. Don’t skip that last link. It explains why your results can be statistically significant one day and not the next. It’s absolutely critical that you set a time period for your test and that you respect it.
Do make sure that you are able to collect the data that you need to evaluate the results. For emails, this includes:
- The number of recipients in the variable group
- The number of recipients in the control group
- The number of people who opened your email in the variable group
- The number of people who opened your email in the control group
- The number of people who clicked on your email in the variable group
- The number of people who clicked on your email in the control group
Note that I specified the number of people not the number of opens or clicks. Unless you get some value out of the same person opening or clicking on your email over and over again, be sure to look at the number of people taking action and not the number of actions taken.
Once you have all this data you are ready to evaluate your results.
Evaluate Results
For evaluating email tests, I like to put together a grid like so for each test:
 Then the very first thing I do is I check for statistical significance. For those of you who aren’t great with math or statistics that can be a big scary word. But it’s this simple. Statistical significance is a measure of how likely your results are repeatable. So for example, if you ran your experiment, how likely would you be to get the same result.
Then the very first thing I do is I check for statistical significance. For those of you who aren’t great with math or statistics that can be a big scary word. But it’s this simple. Statistical significance is a measure of how likely your results are repeatable. So for example, if you ran your experiment, how likely would you be to get the same result.
Typically, we say that if you have a 95% chance of repeating the results, your results are statistically significant. Some people push for a 99% chance. It’s up to you. Below 95% chance, you are probably gambling.
Let’s look for a minute at how statistical significance relates to sample size and the size of the difference in your outcomes. If you have a small sample size, let’s say a variable and control group of 1,000 people each, even big changes in the conversion rate may not be significant. You can see on the chart below that it’s not until the difference in conversion rate is 3% before we reach statistical significance.
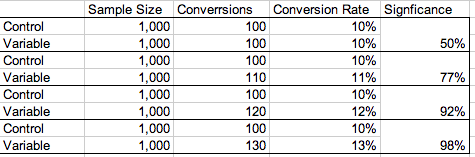
But as your group size gets larger, the probability of your outcome being significant increase. Here, a difference of only 0.3% is significant.
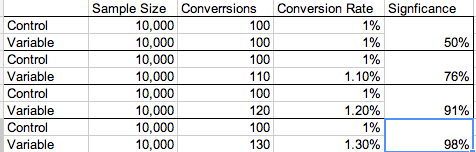
In both cases, the relative percent increase stays the same. We had to see a 30% increase in our conversion rate before we reached statistical significance. But for our smaller sample, a 30% increase was 3 percentage points, whereas in our larger sample, a 30% increase was 0.3 percentage points.
So a good rule of thumb is that if you are working with small sample sizes, you need to look for big wins. You aren’t likely to get statistically significant results if a change that grows your open rates by 1 or 2% But as your sample size increases, growing your open rates by 1 or 2% percentage points not only has a much bigger impact on your outcomes, but you are also likely to get statistically significant results.
If all of this is too confusing, just remember this. You don’t want to look for a 1 or 2% improvement in your email conversion rates. You want to look for big wins. Ask yourself, how can i go from 20% open rate to 40% open rate, not how can I go from 20% open rates to 22% open rates, and you’ll be fine.
Okay, now that we’ve got a handle on statistical significance, let’s get back to our emails. The first thing you want to understand is what part of your grid is statistically significant.
Use this simple statistical significance calculator to check your results. Start by plugging in the number of recipients and the number of people who open you email for both your variable group and your control group. If the difference is significant, it tells you that the difference in your open rate is statistically significant. If it’s not, you can’t learn anything about open rates from this experiment – even if it looks like you can. It’s really important to build in the discipline from day one to only consider statistically significant results.
To determine if your click through rate is statistically significant, plug in the number of people who opened your email and the number of people who clicked on your email for both your variable and control group and check for statistical significance. If you are dealing with small variable groups, it can be hard to get statistically significant results for click through rates because they are limited by those who open your emails. So you might have to improve your open rates before you can run statistically significant tests on your click through rates.
Now it is possible that your conversion rates can be statistically significant while your click-through rates are not. To calculate the statistical significance of your conversion rates, plug in the number of recipients and the number of people clicking for both your variable and control group. If your conversion rates are significant, but your click-through rates are not, be careful about the conclusions that you draw. You can conclude that the winning group converts better, but you can’t conclude that your change improves click-through rates. You will need to do further experimentation to determine that.
Draw Conclusions
Now sometimes your results will be significant but negative, meaning they refute your hypothesis. That’s okay. You still learned something. Here’s a quick cheat sheet of what you can take away from your results.
If your results are not statistically significant:
If your sample size was large, it’s possible that you learned that there your change made no impact. If your sample size is not very large, it’s possible you need to run the test again with a larger sample size.
If your results are statistically significant and support your hypothesis:
This is what you are hoping to see. You learned that the change you made had the impact you expected.
If your results are statistically significant and refute your hypothesis:
This might seem like a bad result, but it’s not. You still learned something. In fact, you probably uncovered an assumption that you thought to be true and discovered that it’s probably not. While these results can be disappointed, they can have the biggest impact on driving outcomes, as they help you uncover things that you believe that are simply not true.
Regardless of the results, you want to be careful about the conclusions that you draw. You need to be careful that you aren’t overreaching in your conclusions. For example, suppose we learn that:
- Including an expiration date in the subject line does increase open rates.
We don’t want to conclude that creating a sense of urgency increases open rates. This is overreaching. If we test several different ways of creating urgency and they all increase open rates, then we might be able to build a case for this conclusion. But right now, all we know is that including an expiration date increases open rates.
Similarly, we want to be careful about what context we are applying our results to. If we ran our experiments on one audience, the results may not carry over to other audiences. Again, if you run multiple experiments across many types of audiences and your hypothesis holds true across all audiences, then you can start to build your case for the broader generalization.
With A/B testing, it’s really important to be honest with yourself about what you actually learned and where you can apply it. The more diligent you are, the more you will learn. Often times, an A/B test will raise further questions helping you to determine your next round of tests. The goal should be to build up a knowledge base over time that allows you to start to generalize what works for your product and your company. More on that in the next post.
Was this helpful? What did I miss? What questions do you have about A/B testing? Have you encountered any problems that I didn’t cover?
[…] ← How To Run an A/B Test […]